Kandula Neha* | Jahangeer Sidiq | Majid Zaman
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
An important concern for students at all levels, from universities to colleges to junior high and high school, is predicting academic achievement and individual performance. Class tests, homework, lab exams, general tests, and final exams all have an impact on a student's academic success or failure. Students' progress can be assessed by looking at their grades in core subjects and electives. The majority of research, on the other hand, says that a student's achievement is best measured by graduation. Researchers set out to develop mathematical models that may be utilized to forecast student academic performance evaluations based on internal and external type predictive indicators. Multiple predictive variables are taken into account for the assessment of student performance while modelling an efficient template for student performance assessment. The proposed model uses Deep Neural Network (DNN) in the process of considering the predictive variables and evaluating student performance using the variables. The proposed model is compared with the traditional models and the results represent that the proposed model accuracy levels are high contrasted to existing models.
predictive variables, deep neural networks, internal type variables, external type variables, performance evaluation
Predicting student performance is a critical area of study for educational institutions such as schools and universities, as it enables the development of effective procedures among other things that increase academic achievement and avoid dropout [1]. Automation plays a large role in many common student activities that deal with large amounts of data gathered from software programmes for technology-enhanced teaching. As a result, careful examination and processing of this data may provide important details regarding students' comprehension and relationship to academic assignments [2].
Before and throughout the semesters, educational administrators and policymakers [3] must design and validate a prediction model for measuring students' academic performance in order to put in place pedagogical and instructional strategies. A deep neural network model is used in this study to build and analyse the complicated nonlinear interaction between cognitive and psychological aspects affecting the academic performance of graduate students [4].
In evaluating college students, academic achievement is the most important criterion. It is the key criterion by which universities evaluate and choose students and monitor the quality of teaching [5]. Most institutions are having a hard time attracting new students due to more competitive educational practises [6]. Students' academic performance must be evaluated in order to encourage growth [7] and improve higher education quality. Numerous factors, including the student's socioeconomic background [8] and previous academic accomplishment, may have an impact on their academic performance, complicating the picture. There has been surprisingly little study into using statistics to analyse and predict students' success in a single problem formulation [9].
Complex interactions can be analysed with the use of machine learning, which is used in applied science [10]. It is capable of self-learning without being explicitly programmed. While the ANN model has a long history in computer science and data science, it is growing more popular and is finding new applications [11]. By using ANN, it is now possible to analyse large amounts of data that are impossible to simplify using normal statistical methods. If the dependent and independent variables have non-linear relationships, then indirect non-linear connections can be found. The ANN has grown in popularity and has demonstrated great efficiency in pattern identification, categorization [12], forecasting, and prediction in healthcare, climate and weather, financial markets, and other fields [13].
However, educational research has only used a small amount of ANN. As modular networks become more complicated, it becomes more difficult to provide a reasonable explanation for them, as well as the models' tendency to fail and the length of time it takes to train them. An area of expertise for both commonly used statistics and ANN evaluation is compromised in this study in order to overcome restrictions by deploying deep neural networks [14]. The analyses of the education data will be done using traditional statistical methods, variables and statistical data will be used for ANN training, validation and testing in order to develop an ANN model with appropriate configuration settings which can predict and classify the performance of the students accurately [15].
The student information acquired from the numerous sources is used for simple query selection, but due to the intricate and noisy structure of datasets, a considerable quantity of data is not yet employed [16]. Researchers at Educational Development Plan (EDP) have concentrated substantially on student educational data to reveal relevant information such as predictions of student performance [17]. In order to reliably estimate student performance using past data, this requires the development and deployment of advanced computational intelligence techniques in the field of Education Data Mining (EDM). Several studies analysed the improvement of the formative assessment of historical data using EDM approaches [18].
ML classifiers have been used to predict whether students will pass or fail binary exams [19]. However, predicting whether a student will pass or fail does not provide us a clearer picture of their academic performance. Another key technical flaw is their failure to evaluate both internal and external factors when evaluating the total influence of predictor factors on student data [20]. As a result, conventional classifiers aren't very good at predicting kids' academic success based on historical data [21]. Several applications, such as rumor-spotting, extremist membership detection [22] and others, benefit from an updated function selection technique enabled by a deeper neural network model [23].
In recent research, it has been found that the quality of undergraduate students is low because of flaws in the present admissions method and an expanding imbalance between the number of individuals applying for admission and the overall acceptance available [24]. Many obstacles have been placed in the path of educational policymakers and administrators. At order to improve education and learning in universities and colleges, it is required to evaluate and implement pedagogical and educational methods. A technique for early evaluation and analysis of student academic success is required to achieve the aforementioned goal, and children in each group must be better served as a result. Therefore, before students reach university level, a probabilistic model for estimating their early academic achievement must be developed and performed.
The predictability of student intellectual advancement has been explained in different ways. The following are:
The intellectual ability of children is influenced by a variety of factors, particularly throughout the high school years. The model, which estimates student academic performance, relies heavily on prior knowledge and previous student achievement [25]. Gender, parent employment/literacy, and school type (private/public) are all in question as academic predictors.
The majority of mainstream research relies heavily on academic success to predict outcomes Unlike university students, potential employees only have their academic records to go on. To keep things from going in the other direction, it's important to look at how demographic factors affect academic performance [26]. The study's goal is to apply machine learning to predict student performance [27]. Complex data relations are analysed via machine learning. Even if machine learning isn't pre-programmed, it can nevertheless learn on its own. An increasing number of businesses are turning to artificial neural networks (ANNs) for help with data processing [28]. As a result, it is capable of analysing large datasets and identifying relationships between variables. In order to develop a neural network that can accurately predict student performance, this study [29] is being conducted. To improve the accuracy of the predictive device, the system was trained and evaluated using data from previously graduated students.
Deep learning is a subset of artificial intelligence's larger field of study. By experimenting with multiple models, deep learning attempts to understand the complexities of various types of acquired data and to choose the most appropriate model for that data. This is done to make things easy for the general public to understand and make use of. Computing algorithms are employed to solve problems, but deep learning is a distinct branch of computer science. It is possible for the system or computer to analyse incoming data, build training sets, and produce output within a specified range using statistical estimation throughout the deep learning process.
Performance evaluation is a critical component of a student's professional and personal growth. Students' strengths and talents are highlighted in performance evaluations. They can use this to enhance their strengths and identify opportunities for improvement. Teachers can use performance evaluation to assist students reach their goals, and vice versa. Teachers that have the ability to analyse their students' performance can focus their efforts on the areas that need it, provide guidance and advise to their pupils, and recognise and reward their efforts.
For a number of reasons, the prediction of educational outcomes has long been considered a crucial area for research in many academic disciplines. First, predictive models can assist the instructor in predicting academic performance of students and subsequently with preventive action. A verified predictive model allows a teacher to identify risky students academically. For example, if a model predicts that a student will get a final exam score below 50, he or she is at risk from academia. The student could first be interviewed and then his/her class performance is observed. This helps the instructor to understand the learning talents and issues of the student. Based on the opinion of the instructor, more educational interventions on the student can be implemented.
Vairachilai and Vamshidharreddy [1] gave a comparison of a number of classification algorithms, including the decision tree, the Support Vector Machine (SVM), and Nave Bayes. Researchers Li et al. [3] exploited the Internet to predict student performance. This year, project courses and network logs used online learning records. Predicting student success in a class has been done using a Deep Network. They have achieved 72% percent accuracy rate. Researchers Wei et al. [4] proposed interactive online pools to improve student performance prediction, as well as taking into account the interaction between student qualities. First drag and drop and first attempt were introduced as new features. To do this they used a multi-layer perceptron to predict the performance of students who were attending classes.
Using the ensemble model to improve student graduation prediction was the focus of a study by Lagman et al. [6]. Identifying students who are highly unlikely to have a degree is the goal. These children can be identified in places that are lacking in resources, allowing them to receive the care they need. In the best case scenario, a precision of 77 percent might be obtained on average. Using Moodle data for higher education, Quinn et al. [7] evaluated the academic performance prediction of students. According to their research, students' academic progress might be predicted based on data from the Moodle Learning Management System (LMS).
Using huge data in teaching was the subject of a research suggested by Sin et al. [8]. A wide range of learning analysis methods rely on big data, including prediction and visualisation, risk detection and evaluation of student ability levels and training recommendations systems. Other methods include grouping students and fostering collaboration between many other students. Predictive analytic features are emphasised in this study as well as the performance, behaviour and skill prediction of students. Using academic data Polyzou et al. [10] research aims to create collaborative filters for predicting students' achievement. The results of the experiments reveal that the technique is more effective than the standard support vector machine classifier.
A technique based on low-speed matrix factorization and distributed linear models was proposed by Thai-nghe et al. [11] for evaluating a student's performance based on their previous academic grade data. For around 10 years, the University of Minnesota's academic student cases have been included in the dataset. The proposed method improves grade prediction accuracy. Using a recommendation algorithm to extract educational data is a new method. The technique was created primarily to predict student success in a matrix factorization learning environment. In order to validate the recommendation system, it must be compared to other cutting-edge regression models, including linear and logistic regression. Adding a recommendation engine to the proposed system is another way to enhance the system.
A machine-based learning strategy combining two cutting-edge classifications, namely the decision tree and Nave Bayes, was suggested when constructing a categorization system for students proposed by Hussain et al. [13]. The data came from a variety of colleges. When it came to predicting grades, "father occupation" was noted among other factors. Researchers found that decision tab classification was more accurate than Nave Bayes classification. There are many tools and technologies that can be employed in education to improve learning and teaching. According to Sekeroglu et al. [18], there is a link between big data and education. On the basis of Spark and Hadoop, a sophisticated recommendation system is constructed in order to find links between undergraduate academic activities. Techniques for unattended machine training, such as association rule mining are considered and analysed.
An advanced and difficult method for modelling nonlinear functions, which is how most real world systems are characterised, is ANN. An ANN's input, hidden and output layers consist of three layers of neuron layouts. This layer is used to collect feature sets and activation variables, which are then used to create numerical information [30]. The input data is sent to the hidden layer by the linked neurons. There, input neurons are weighted and added together, and the output layer uses an activation function to get the final result. During the learning process, the weights of both neurons and connections can be adjusted. If the activation function level is exceeded, the summed neurons will experience a mathematical change at the output layer.
"Epoch" is the name given in ANN to the number of times the connection weights are updated by the training functions during the process of feeding input data or variables and completing with output data. Weights are combined with fake neuron inputs in this layer. The resulting weights are then delivered to the output layer through an activation function. Linguistic functions such as the sigmoid and hyperbolic tangent functions are some of the more common ones. As part of training, a maximum epoch value or number of validation tests are performed.
Students' academic success is affected by a variety of circumstances, according to study such as demographics and extra-curricular activities, as well as environmental and biological factors.
One of the most significant and hardest responsibilities for educational institutions is predicting student performance. This is especially true for e-learning environments at the university level. As long as the demographics of the students and their performance on particular activities are assessed, solid training may be provided with the data for a machine-supervised learning method. More accurate models can be created by integrating other data, such as total grade point, grades in other courses, and scores on a variety of different assessments. A closer look at the prediction results may reveal a relationship between different features, therefore it's best to look at a few extras in this regard.
Based on their first semester courses, the students' performance is initially predicted. Finding patterns between student grades from past classes may help us forecast a student's performance. Students, assignments, and grades were represented by large sparse matrices in small universities or classes with few students. According to the outcomes of this investigation, the accuracy of predictions was lower than predicted. There was a need for more information from the students or assignments. Planning educational interventions aimed at improving student learning outcomes and preserving government resources, as well as educators' time and effort, requires a high level of precision. When combined with classification algorithms, the use of pre-processing techniques improves predictive power.
A student's behaviour and other pertinent factors can be used to predict their final performance related to learning results. According to a weekly ranking system, students' chances of being classified as high, medium, or low performers were determined. As an alternative to using course-dependent formulas to evaluate performance, historical data appears to be more useful. Deep Learning discipline has successfully used clustering techniques with good outcomes. According to their performance, recursive clustering, for example, assigns students to certain courses based on their performance. Each of these groups receives a specific set of programmes and remarks based on their membership. This approach is used to transition students from lower-level groups to higher-level groups. Although this is the case, each student has their own distinct qualities that must be considered. A student's specialisation might be established based on a specific evaluation of their performance. Based on a system of personalised prediction, particular criteria including fundamental courses, prerequisites, and course levels were analysed for computer speciality courses.
Artificial neural networks were used to forecast student achievement. As an illustration, consider a synthetic neural network, which contains many neurons as well as hidden and output layers. It is possible to anticipate how well a model will perform if you utilise weights. Because of the interdependence between the weights and the network structure, this is a time-consuming procedure. The network includes two phases: learning and prediction. Learning is an ongoing process. The weights are re-adjusted to a desired result during the learning process. After that, if the criterion isn't met, the process is cycled through again. Termination criteria include acceptable mean squares or the number of evolutions required to obtain a certain goal value, depending on the application. After training, an ANN is put to the test and validated. Unknown samples are utilised for testing and validation as part of the ANN's training.
Several variables in semester-wise are used to analyse student data in the research proposal, with assignments, attendance, internals (lab performance), seminars (technical presentations), and group discussions), and external factors (behaviour) such as talkative skills and talkative abilities all being taken into account.
${{\mathrm{VS}}[]} \leftarrow\{\mathrm{AM}, \mathrm{AT}, \mathrm{IM}, \mathrm{PM}, \mathrm{LM}, \mathrm{SM}, \mathrm{TPM}, \mathrm{GDM}, \mathrm{BL}, \mathrm{TSL}\}$
where, AM is the Assignment marks, AT is the Attendance Level, IM is the Internal marks, PM is the project marks, LM is the lab marks, SM is the Seminar marks, TPM is technical presentation marks, GDM is the group discussion marks, BM is the behaviour level and TSL is the talkative skills level. The external and internal variables are combined in the process of semester wise student assessment.
The input variables are collected during pre-admission for a new student and previous semester results for existing student using feature sets and feeds it to the hidden layer. A vector output values are produced using the weighted sum of its input variable elements Level L and Improvement Range IR.
${{V}_{i}}=\theta \left( \sum\limits_{i=1}^{{{N}_{i}}}{I{{R}_{ij}}{{L}_{i}}} \right)+\max (Variables)$
Here θ is considered as the activation function in the process of performance assessment, Ni is the total number of student variables to the jth neuron and IRi is the output value from the previous layer of ith neuron. The activation function (θ) of hyperbolic tangent is used to transfer the value of weighted sum of inputs variables to the output layer based on the variable values in every semester. The resultant activated layer assessment for the next input variable level IVL is performed as:
$IV{{L}_{j}}=\theta \left( {{V}_{j}} \right)+\delta $
where, δ is the threshold limit of the variables considered. The outputs that represent the change in the values of input variables is calculated as:
$Output=\left\{ IV{{L}_{Ni}}\left| V\in \min {{(L)}^{N}} \right. \right\}$
The change in the variables values are identified and then the hidden layers are now considered for analysis of the performance in a single semester. The objective function can be given for analysing the minimum range of the performance level of a student that is calculated as:
$OF(F(x,y))={{\sum\limits_{L}{\left[ \max (Output(V)+\max (IVL)-IR(i,j) \right]}}^{2}}+\theta $
The input, hidden, and output layers are all added together to form auto regression R. The transfer function's output is used as an input by the neuron in the layer above. The representation is produced in each neuron as:
$\begin{align} & {{R}_{Ni}}= \\ & \tau anh\left[ \max (AM)+\min (AT)+\max (IM)+\max (PM)+\min (LM) \right]\,+ \\ & \,\left[ \begin{matrix} \max (TPM) \\ 1 \\ 1 \\ \max (GDM) \\\end{matrix} \right]+\left[ \min (BL)+\min (TSL) \right] \\\end{align}$
Average Prediction Accuracy (APA) indicates, on average, how well the model predicts the final exam scores of students in the dynamics course. The average prediction accuracy for the final exam scores was calculated as:
$APA=1-\frac{1}{V}.\sum\limits_{i=1}^{N}{\left| \frac{{{R}_{i}}-{{A}_{i}}-{{L}_{ij}}}{O{{F}_{ij}}} \right|}\times 100%+\theta $
where, N is the total number of students considered for assessment, Ri is the predicted final exam score of the ith student in the class $\left( i=\left[ 1,n \right] \right)$ and Ai is the actual final exam score of the ith student. The higher the average prediction accuracy, the better the model.
The student performance is calculated using the SoftMax function as:
$\lambda \left( {{x}_{i}} \right)=\frac{\max {{(APA)}^{{{N}_{i}}}}+\max (R)}{\sum\nolimits_{k=1}^{12}{Vi}}$
The mean square error of the proposed model is performed as:
$MSE=\frac{1}{{{V}_{i}}{{L}_{j}}}\sum\limits_{j=1}^{{{N}_{j}}}{\sum\limits_{i=1}^{{{N}_{i}}}{{{\left( {{\lambda }_{ij}}-AP{{A}_{ij}} \right)}^{2}}+\theta }}$
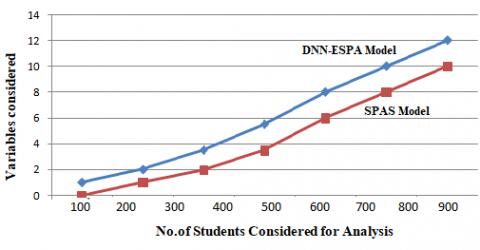
In this research work dataset is considered from the link https://www.kaggle.com/aryanml007/students-performance-analysis/data. This dataset has several factors like assignment, attendance, internals, project, laboratory performance, seminar, technical presentations and group discussions and external factors like behaviour and talkative skills which have an impact on the overall success of the student. Furthermore, a standard programming tool python is used for generating a prototype based on the data set that has been chosen. This data collection is further broken down into two components Test Data-Set and Training Data-Set. In order to accurately predict student performance, the suggested model takes both internal and external factors into account. Student Performance Analysis System (SPAS) Model is compared to the proposed Deep Neural Network for Evaluating Student Performance Assessments. Variables such as Pre Admission Assessment Accuracy Levels, Semester-Wise Improvement in Student Performance, Student Grade Improvement Level and Student Performance Assessment Levels are compared between the new model and the old one to see which one performs better overall. Figure 1 depicts the characteristics that were taken into account in both the new and old models, depending on which one you prefer. For correct assessment of pupils' performance, the variables are responsible.
Performance-based evaluations have in common the ability to precisely measure one or more course criteria, which is their defining feature. As well as being open and time-bound, they're also honest, process/product-oriented, and complex. Class tests, homework, lab exams, general tests, and final exams all have an impact on a student's academic success or failure.
Figure 1. Variables considered
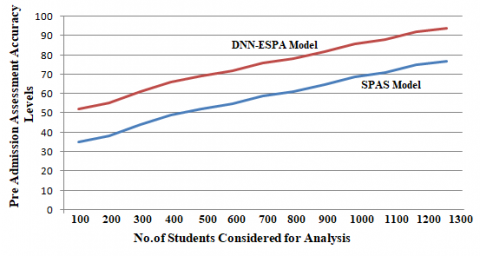
Figure 2. Pre admission assessment accuracy levels
Performance analysis of learning-based results is a system that seeks excellence at many levels and dimensions in the benefit of students. This technology has been built to examine and solely predict the performance of the student before pre admission by considering the previous academic track. The framework presented evaluates the demographic, study-related and psychological features of students to obtain all possible information from students, instructors and parents. The number of higher education universities/institutions has increased during the last decade. They generate a huge number of graduates every year. Universities and institutions can pursue their pedagogical approach better, but still deal with the issue of dropouts, poor students and jobless students. The pre admission assessment is very much helpful in assessing the students and the accuracy levels of the proposed and traditional models are shown in Figure 2.
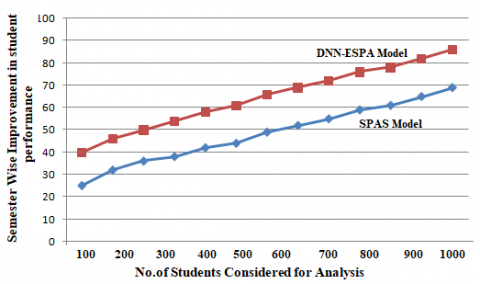
Model Evaluation in semester wise is a vital aspect of the process of model creation. This helps to determine the optimal model for our data and how well the model chosen will function in the future. In the data science it is not acceptable to evaluate predictive accuracy with the training data because it can easily develop overoptimistic and over fitted models. The semester wise improvement in students is considered that shows the improvement of the proposed model. The semester wise improvement levels of the proposed and traditional models are represented in Figure 3.
Due to the sheer amount of input in academic databases, it has become harder to forecast students' success. There is also now no consideration of the lack of a set framework to evaluate and measure student achievement. The students have to improve the grade in their academics for improving the performance. The student grade improvement levels of the proposed and existing models are represented in Figure 4.
Figure 3. Semester wise improvement in student performance
Figure 4. Student grade improvement level
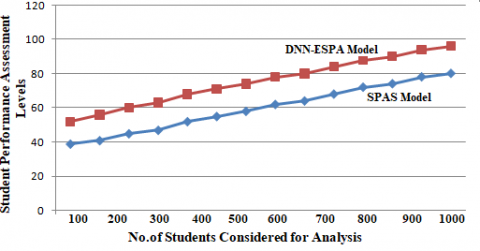
Figure 5. Student performance assessment levels
One of the advantages of the student prediction is that it decreases the official warnings and drives students because of their inefficiency. Academic institutions attempt to create the student model to anticipate each student's particular features and performance. The student performance Assessment levels of the proposed and traditional model are shown in Figure 5.
The proposed model performs better in student performance evaluation and the accuracy levels in the assessment is also high in the proposed model. The accuracy levels, precision, recall levels are represented in Table 1.
Table 1. Proposed method with respect to DL models
|
Method |
Acc. (%) |
P(%) |
R(%) |
F-Score (%) |
|
Deep Learning Techniques |
||||
|
Recurrent Neural Network (RNN) |
72.55 |
0.76 |
0.62 |
0.82 |
|
Convolutional Neural Network (CNN) |
76.57 |
0.72 |
0.71 |
0.79 |
|
Long Short - Term Memory (LSTM) |
74 |
0.89 |
0.74 |
0.84 |
|
Bidirectional Long Short-Term Memory (BiLSTM) |
82.7 |
0.78 |
0.82 |
0.86 |
|
Proposed DNN-ESPA Model |
96.24 |
0.95 |
0.91 |
0.92 |
We discovered that there is a high proclivity to forecast student performance at the university level, since about 70% of the papers examined in our study are for this purpose. This may persuade us to pursue additional research efforts to solve shortcomings in other areas. As a result, it is intriguing to promote working techniques to apply these predictions at the university level, which would aid in identifying students' poor performance at an early age. Analysis of student dropout in the early stages is particularly intriguing, because there are still opportunities to investigate helpful prevention approaches. The grades or points obtained by a student in preliminary courses may not really reflect the student's knowledge of those subjects. A student might have taken preconditional courses years ago. When variables are considered dynamically, it may have increased its knowledge of prior courses and the prediction of performance will be accurate. According to this viewpoint, a viable study technique would be to apply, in addition to evaluate predictive approaches used for university performance. Although neural networks have a high level of accuracy in anticipating student performance, they are a technology that is rarely used. Predicting student performance based on historical data is a critical task. Furthermore, only key elements are included for prediction, despite the fact that additional characteristics, such as student social and cultural attributes and time spent on a certain activity, can result in higher performance. In this research work, a deep learning model is introduced to predict the student performance by considering several variables in evaluating their performance. Multiple data sets with more types of fused deep learning models will need to be investigated in the future.
[1] Vairachilai, S., Vamshidharreddy. (2020). Student’s academic performance prediction using machine learning approach. International Journal of Advanced Science and Technology, 29(9s): 6731-6737.
[2] Ofori, F., Maina, E., Gitonga, R. (2020). Using machine learning algorithms to predict students’ performance and improve learning outcome: A literature based review. Stratford Peer Reviewed Journals and Book Publishing Journal of Information and Technology, 4(1): 33-55.
[3] Li, X., Zhu, X., Zhu, X., Ji, Y., Tang, X. (2020). Student academic performance prediction using deep multi-source behavior sequential network. Advances in Knowledge Discovery and Data Mining. PAKDD 2020. Lecture Notes in Computer Science, 12084: 567-579. https://doi.org/10.1007/978-3-030-47426-3_44
[4] Wei, H., Li, H., Xia, M., Wang, Y., Qu, H. (2020). Predicting student performance in interactive online question pools using mouse interaction features. LAK 2020. arXiv:2001.03012.
[5] Yahaya C.A.C., Yaakub C.Y., Abidin A.F.Z., Razak M.F.A., Hasbullah N.F., Zolkipli M.F. (2020). The prediction of undergraduate student performance in chemistry course using multilayer perceptron. The 6th International Conference on Software Engineering & Computer Systems; IOP Conf. Series: Materials Science and Engineering, 769: 012027. https://doi.org/10.1088/1757-899X/769/1/012027
[6] Lagman, A.C., Alfonso, L.P., Goh, M.L.I., Lalata, J.P., Magcuyao, J.P.H., Vicente, H.N. (2020). Classification algorithm accuracy improvement for student graduation prediction using ensemble model. International Journal of Information and Education Technology, 10(10): 723-727. https://doi.org/10.18178/ijiet.2020.10.10.1449
[7] Quinn, R.J., Graya, G. (2020). Prediction of student academic performance using Moodle data from a Further Education setting. Irish Journal of Technology Enhanced Learning, 5(1). https://doi.org/10.22554/ijtel.v5i1.57
[8] Sin, K., Muthu, L. (2015). Application of big data in education data mining and learning analytics-A literature review. ICTACT Journal on Soft Computing, 5(4): 1035-1049. https://doi.org/10.21917/ijsc.2015.0145
[9] Mizumoto, T., Ouchi, H., Isobe, Y., Reisert, P., Nagata, R., Sekine, S., Inui, K. (2019). Analytic score prediction and justification identification in automated short answer scoring. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, Florence, Italy, pp. 316-325.
[10] Polyzou, A., Karypis, G. (2016). Grade prediction with models specific to students and courses. Int. J. Data Sci. Anal., 2: 159-171. https://doi.org/10.1007/s41060-016-0024-z
[11] Thai-nghe, N., Drumond, L., Krohn-grimberghe, A., Schmidt-thieme, L. (2010). Recommender system for predicting student performance. Procedia Comput. Sci., 1(2): 2811-2819. https://doi.org/10.1016/j.procs.2010.08.006
[12] Khan, B., Khiyal, M.S.H., Khattak, M.D. (2015). Final grade prediction of secondary school student using decision tree. Int. J. Comput. Appl., 115(21): 32-36. https://doi.org/10.5120/20278-2712
[13] Hussain, S., Khan, M.Q. (2021). Student-performulator: Predicting students’ academic performance at secondary and intermediate level using machine learning. Ann. Data Sci. https://doi.org/10.1007/s40745-021-00341-0
[14] Dahdouh, K., Dakkak, A., Oughdir, L., Ibriz, A. (2019). Large-scale e-learning recommender system based on Spark and Hadoop. J. Big Data, 6: 2. https://doi.org/10.1186/s40537-019-0169-4
[15] Ebenezer, J.R., Venkatesan, R., Ramalakshmi, K., Johnson, J., Glen, P.I., Vinod, V. (2019). Application of decision tree algorithm for prediction of student’s academic performance. International Journal of Innovative Technology and Exploring Engineering (IJITEE), 8(6S).
[16] Zohair, L.M.A. (2019). Prediction of student’s performance by modelling small dataset size. Abu Zohair International Journal of Educational Technology in Higher Education, 16: 27. https://doi.org/10.1186/s41239-019-0160-3
[17] Buenaño-Fernández, D., Gil, D., Luján-Mora, S. (2019). Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability, 11(10): 2833. http://doi.org/10.3390/su11102833
[18] Sekeroglu, B., Dimililer. K., Tuncal, K. (2019). Student performance prediction and classification using machine learning algorithms. ICEIT 2019: Proceedings of the 2019 8th International Conference on Educational and Information Technology, Cambridge, United Kingdom, pp. 7-11. http://doi.org/10.1145/3318396.3318419
[19] Rastrollo-Guerrero, J.L., Gómez-Pulido, J.A., Durán-Domínguez, A. (2020). Analyzing and predicting students’ performance by means of machine learning: A review. Appl. Sci., 10(3): 1042. https://doi.org/10.3390/app10031042
[20] Hamoud, A.K., Humadi, A.M. (2019). Student's success prediction model based on artificial neural networks (ANN) and a combination of feature selection methods. Journal of Southwest Jiaotong University, 54(3). https://doi.org/10.35741/issn.0258-2724.54.3.25
[21] Imran, M., Latif, S., Mehmood, D., Shah, M.S. (2019). Student academic performance prediction using supervised learning techniques. Int. J. Emerg. Technol. Learn., 14(14): 92-104.
[22] Sultana, J., Rani, M.U., Farquad, M.A.H. (2019). Student’s performance prediction using deep learning and data mining methods. Int. J. Recent Technol. Eng., 8: 1018-1021.
[23] Sidiq, S.J., Zaman, M., Butt, M. (2018). An empirical comparison of classifiers for multi-class imbalance learning. International Journal of Data Mining and Emerging Technologies, 8(1): 115-122.
[24] Ashraf, M., Zaman, M., Ahmed, M., Sidiq, S.J. (2017). Knowledge discovery in academia: A survey on related literature. Int. J. Adv. Res. Comput. Sci, 8(1): 303-310.
[25] Sidiq, S.J., Zaman, M., Ashraf, M., Ahmed, M. (2017). An empirical comparison of supervised classifiers for diabetic diagnosis. Int J Adv Res Comput Sci, 8(1): 311-315.
[26] Neha, K., Sidiq, S.J. (2020). Analysis of student academic performance through expert systems. International Research Journal on Advanced Science Hub, 2(9s): 48-54. https://doi.org/10.47392/irjash.2020.158
[27] Sidiq, S.J., Zaman, M. (2020). A binarization approach for predicting box-office success. Solid State Technology, 63(5): 8652-8660.
[28] Sidiq, S.J., Zaman, M., Butt, M. (2018). A framework for class imbalance problem using hybrid sampling. Artificial Intelligent Systems and Machine Learning, 10(4): 83-89.
[29] Sidiq, S.J., Zaman, M., Butt, M. (2018). A comprehensive review on class imbalance problem. Artificial Intelligent Systems and Machine Learning, 10(3): 59-65.
[30] Neha, K. (2021). A study on prediction of student academic performance based on expert systems. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 12(7): 1483-1488.