Ashish Ranjan* | Vibhav Prakash Singh | Anil Kumar Singh | Anil Kumar Thakur | Ravi Bhushan Mishra
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
aBrain being the most complex organ of human body in which millions of neuron are connected to each other, and pass information in processing of thoughts, emotions, motor activities and linguistic phenomenon. With the advent of non-invasive neuro-anatomical analysis methods like PET scan, fMRI it is now easy to measure neuronal changes in brain. This study analyses the neuronal activity in the brain in sentence polarity detection task using multilayer perceptron classification methodology. The whole brain is divided into almost 5000 three-dimensional volume called voxels from which prominent voxels are selected using symmetrical uncertainty based on entropy for the classification of brain state. The proposed method achieved significantly higher accuracy in classifying brain state in the processing of affirmative and negative sentences. The result obtained also shows that certain brain regions like left dorsolateral prefrontal cortex (LDLPFC) and calcarine sulcus (CALC) are prominent areas which are deterministic in classification of affirmative and negative sentences in brain while right posterior pre-central sulcus (RPPREC) and right supramarginal gyrus (RSGA) are less contributing.
fMRI, voxel, ANN, entropy, sentence polarity
The brain is the most complex organ of the human body, responsible for every thought, emotions, feelings, and experiences. It has very complicated neuronal connectivity where each neuron connects with thousands or ten thousand neurons with synapse. The connections and the strength of connection change continuously, and our brain forms millions of new connections every second, which makes it possible to store memories, to learn habits and to shape personalities by reinforcing specific patterns of activities and losing some others. It is found that no two brains are alike, and grey matter in the brain is cell bodies, whereas the white matter is a connection of thread-like structure called axons and dendrites, which connects cell bodies to other neurons. The signals between neurons pass by the release and the capture of neurotransmitter and neuromodulator chemicals like glutamate, acetylcholine, noradrenaline, dopamine, endorphins, and serotonin. The electrochemical signals of neuronal activity are recorded on the scalp using electroencephalography.
In contrast, indirect measurement of neuronal activities is recorded by PET scan and fMRI, which monitor blood flow and CT, and DTI uses the magnetic signature of different tissues. These scanning techniques have revealed which parts of the brain are associated with which functions. Right handed subjects showed right-hemispheric attentional dominance in 95% of cases, and left-hemispheric language dominance in 97% of cases. Left-handed subjects displayed right-hemispheric attentional dominance in 81% of cases, and left-hemispheric language dominance in 74% of cases [1]. Results are in agreement with previous observations ascribing a pre-eminence of the right hemisphere in the processing of negative affective responses in right handed individuals [2]. fMRI study of language processing and its various aspects like syntax, semantics, morphology, etc. in the brain is analyzed for decades.
The processing of syntax in the brain is quietly different from that of –morphology, semantics, etc. [3]. The study and the representation of the syntax (sentence structure) in the brain based on neuroimaging data are enriched in new findings. The research of the syntactic brain grounded on fMRI data can be viewed in five types of sentence arrangements in literature. A) Syntactic violations B) Complex vs. simple sentences C) Sentence vs. word list D) sentences containing pseudo words E) sentences having separate agreements and types.
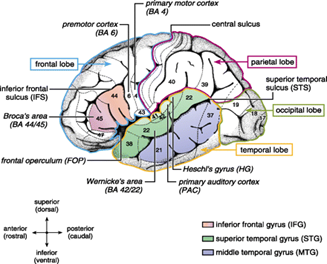
In case of syntactic violation, in which the sentences are syntactically correct but semantically incorrect or having some grammatical error, or spelling error caused increased activation in areas that are involved in syntactic processing due to disruption in agreement checking and structure building which results in more attentive behavior [4]. More superior frontal activity (BA 6, 8) is found for syntactic error compared to any other errors. In grammatical vs. ungrammatical sentences, both types of sentences were presented to the subject, and corresponding fMRI activation was recorded. Syntactically correct and incorrect sentences have different activation patterns and areas of activation in the brain [5]. For complex and simple sentences, the complex sentence involves more syntactic operations, i.e., more reconstruction and canonical word ordering hence activates more area than simple sentences [6]. The enhanced activation in complex sentences lies in Broca’s area (BA 44, 45) extended to BA 47, 6, and 9 [7]. Some additional activation is found in left bilateral superior and middle temporal gyri (BA 21, 22) left angular/supramarginal gyri (BA 39, 40) and cingulate gyrus (BA 23,24,31,32). In the case of sentence vs. word list where a comparison is made between sentence, i.e., syntactic structure and a list of unrelated words, an increased activation is observed for sentence in the anterior part of the temporal lobe, especially temporal pole (BA 38). In addition to this, superior and middle temporal gyri (BA 22 and 21) are also found activated [8]. The comparison of the simple sentence with the pseudoword containing sentences, i.e., sentences that are syntactically correct but consisting of meaningless words (pseudo-words), yielded activation in the posterior superior temporal sulcus (BA 22,41/42). Additionally, anterior superior temporal sulcus (BA 38,22) was also found activated. Figure 1 shows the different brain regions [9] involved in language processing tasks.
However, syntactically and semantically correct sentences are studied by altering its structure and agreements. Lots of research has been done to date, where different forms of sentences are reviewed. Yokoyama et al. [10] have demonstrated the mechanism of case processing in our brain, and the result found shows that the processing of the genitive case activates the left inferior frontal gyrus and posterior part of the middle temporal gyrus more than the nominative case and accusative case for English native speakers.
Figure 1. Brain anatomy for language processing
The negative sentences are having more syntactic structure than that of affirmative sentences since it contains other syntactic entity for negation [11]. Different negative sentences have diverse representations in the brain, depending on whether these include bipolar predicate or contradictory predicate [12]. Processing of negative sentences is assumed to be a two-step process in which, at first, the affirmative form is processed. Then the negative version of it is represented in the brain, whereas affirmative sentences are directly processed in the brain [13]. The additional syntactic transformation reflects greater cortical activation in the case of negative sentences. Higher activation in the left posterior temporal gyrus and the bilateral parietal brain is observed in negative sentences compared to its affirmative counterpart [14]. In the study of Japanese-English sequential bilingual paradigm with target-probe matching task, a significant activation in left temporal and left pre-central gyrus was observed for negative sentences in English, which is the second language for the participants [15]. Study of action related and abstract sentence polarity sentences have revealed a dynamic mental simulation model of negative sentence processing. Increased activation in the left hemisphere perisylvian and parietal was observed for abstract negative sentences, but a partial deactivation was found in action related negative sentences in left pallidum [16]. For the Danish language, increased activation in the left premotor cortex (BA6) for negative sentences was found [17]. This study reveals that there are three most grave cortical centers for the processing of negative sentences- left premotor cortex (BA6) for sentence structure, bilateral inferior parietal (SMG, BA 40) for semantic processing, and left inferior frontal gyrus dedicated for computation of syntactic complexity. The authors examined the neural correlates of the differences between negative and affirmative sentences using functional magnetic resonance imaging (fMRI), and results found showed enlarged activation in left premotor cortex from negation companionable with rule-governed memory processing and increased activation in the right supramarginal gyrus from affirmation, compatible with semantic processing. In fMRI study [18] of sentences having single and double negation for the German language, it is found that left supplementary motor area (SMA(BA6)) left pars triangularies (BA 45) left pars opercularies (BA44)) and left superior temporal gyrus (STG(BA42)) are functionally associated in the processing of main clause negation. IFG (inferior frontal gyrus) plays the most crucial role in the co-ordination of the cortical areas responsible for language processing and logical reasoning in the interpretation of negative sentences. Kumar et al. [19] have examined fMRI data for activation pattern of the brain in the processing of negative/affirmative sentences of Hindi and found that common cortical region involved in processing includes-bilateral inferior frontal gyrus(IFG), left parietal cortex(BA /40), left fusiform(BA37), bilateral supplementary motor area (SMA (BA6)), bilateral temporal gyrus( BA21) and bilateral occipital area (BA17/18). In addition to this, the study of fMRI data shows that the anterior temporal pole is dedicated to the processing of negative sentences.
The data set used in this paper is known as the Star Plus [20] data set, which was collected by Marcel Just and his colleagues at Carnegie Mellon University. The fMRI signals were collected over a grid of 64*64*8 voxel throughout the experiment. The data was collected from six healthy subjects. Each subject was performing a sequence of activities during the entire session of fMRI recording. Activities include showing a picture and descriptions of it in sequence and then pressing a button of yes or no depending upon whether the sentence correctly describe the picture or not. This event-related experiment consists of trials. One trial of experiments lasts for 27 seconds, and at every 500ms interval, fMRI data was recorded for whole-brain; hence a total of 54 images of the brain were recorded in a specific trial of the experiment.
At the start of the experiment, a picture or sentence was presented on the screen for 4 sec, and then after for another 4sec, a blank screen was shown. After that, a picture or sentence was shown again for 4 sec, in which a button was to be pressed for yes or no whether the sentence correctly describes the picture or not. If the first stimulus is shown as a picture, then the second item displayed was a sentence and vice versa. The picture first and sentence after was termed as PS data set, and in the case where the sentence was the first stimulus, the data was termed as SP data set.
In half of the trial, the picture was presented first, and the remaining half trial consists of presenting sentences as the first stimulus. The picture presented in this experiment were geometrical arrangements of $,*, and +. Whereas the sentences presented were a description of picture and half of the sentences were affirmative sentences, and the remaining half were negative sentences. The sentences were just a description of the picture like “it is true that the dollar is above the star” or “it is not true that star is above the plus.” A total of 40 trials were presented to each subject. Each trial consists of around 5000 voxels for one image, so a total of 270000 voxels for one trial of the experiment. The whole brain is divided into 25 ROIs (region of interests) into which different voxel activity pattern resides.
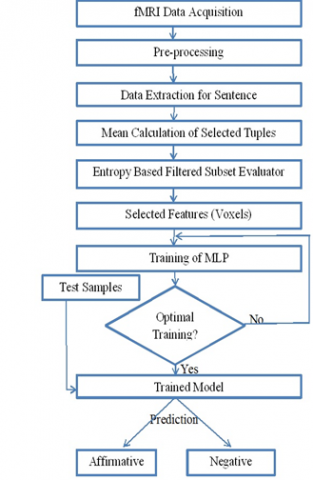
The proposed model utilises correlation based subset evaluator feature selection techniques and multilayer perceptron classification approach in classifying the cognitive state [21] using fMRI data in affirmative and negative sentence processing in the brain. The work flow diagram of the proposed model is represented in Figure 2.
Figure 2. Work-flow diagram of proposed model
3.1 fMRI data acquisition
T2 weighted -fMRI data were collected from 6 healthy people at the interval of every 500ms. In this experiment a 3.0 T GE Sigma scanner was used, having TE=18ms and a flip angle of 50°. The resulting images captured approximately 5000 voxels per subjects in 8 oblique axial slices in two separate non-contiguous four-slice volumes [22].
3.2 Pre-processing
FIASCO program [23] was used in pre-processing of fMRI images to remove artifacts, i.e., head motion and signal drift, and to correct slice timing. Talairach co-ordinate was used for the normalization of data. 25 anatomical region of interests(ROIs) were selected after pre-processing which includes calcarine sulcus (CALC), left dorsolateral prefrontal cortex (LDLPFC) and right dorsolateral prefrontal cortex(RDLPFC), left inferior parietal lobule (LIPL), left frontal eye fields (LFEF), left intraparietal sulcus (LIPS), right frontal eye fields (RFEF), left inferior frontal gyrus (LIFG), right intraparietal sulcus (RIPS) right inferior parietal lobule(RIPL), supplementary motor areas (SMA), left opercularis (LOPER), right opercularis (ROPER), left and right posterior pre-central sulcus (LPPREC, RPPREC), left and right inferior temporal lobule (LIT, RIT), left temporal (LT) lobe, right temporal lobe, (RT)left and right supramarginal gyrus (LSGA, RSGA), left superior parietal lobule(LSPL), and right superior parietal lobule (RSPL) left and right triangularis (LTRIA, RTRIA).
3.3 Voxel distribution area wise
The data was collected from six persons, and each person has its own identifier id or subject id. For all six persons, their identifiers are following- Subject 04799, Subject 04820, Subject 04847, Subject 05675, Subject 05680, and Subject 05710. The data set comprises of fMRI signal distributed over 24 different anatomical regions of the brain. The analysis of the data set reveals that for the same task, the numbers of voxels involved differ not only anatomical area-wise but subject-wise also. The region-wise distribution of voxel activities is presented in Table 1, which shows the distribution of signal data into different regions of the brain.
3.4 Data extraction and averaging
The data corresponding to the sentence processing is extracted according to the Eq. (1).
The extracted data for classifier training takes the form-
$f: fMRI-sequence (t, t+8) \rightarrow {A Affirmative/Negative sentence}$ (1)
from star plus data-set. The symbol t denotes time. Here 8 sec duration is chosen to capture maximum effective activation signal pattern from data set. 16 images are extracted for 8 sec duration. We calculate the mean of these signals for all voxels. The mean of the extracted data is calculated in accordance with Eq. (2).
$\forall j, j \in \operatorname{column}, \sum_{i=1}^{n} x_{i j} / n$ Where $\mathrm{x}_{\mathrm{ij}}$ is an $\mathrm{i}^{\mathrm{th}}$ row and $j \mathrm{th}$ column entry. (2)
Table 1. Number of voxels in each anatomical region of the brain
|
RIO |
Subject 04799 |
Subject 04820 |
Subject 04847 |
Subject 05675 |
Subject 05680 |
Subject 05710 |
|
CALC |
255 |
408 |
318 |
399 |
334 |
219 |
|
LDLPFC |
498 |
501 |
440 |
504 |
614 |
478 |
|
LFEF |
97 |
128 |
109 |
30 |
71 |
124 |
|
LIPL |
299 |
62 |
133 |
263 |
286 |
264 |
|
LIPS |
147 |
155 |
235 |
197 |
196 |
226 |
|
LIT |
366 |
225 |
286 |
233 |
173 |
197 |
|
LOPER |
145 |
103 |
169 |
261 |
235 |
101 |
|
LPPREC |
13 |
190 |
153 |
26 |
53 |
110 |
|
LSGA |
104 |
55 |
7 |
119 |
95 |
127 |
|
LSPL |
171 |
290 |
308 |
265 |
274 |
137 |
|
LT |
340 |
484 |
305 |
476 |
472 |
445 |
|
LTRIA |
190 |
175 |
113 |
136 |
93 |
150 |
|
RDLPFC |
468 |
374 |
349 |
382 |
453 |
419 |
|
RFEF |
81 |
142 |
68 |
45 |
40 |
73 |
|
RIPL |
287 |
46 |
90 |
244 |
215 |
213 |
|
RIPS |
118 |
65 |
166 |
158 |
237 |
185 |
|
RIT |
285 |
187 |
277 |
267 |
151 |
209 |
|
ROPER |
88 |
140 |
180 |
194 |
255 |
108 |
|
RPPREC |
59 |
124 |
144 |
50 |
72 |
43 |
|
RSGA |
71 |
41 |
34 |
54 |
71 |
57 |
|
RSPL |
213 |
238 |
252 |
254 |
213 |
119 |
|
RT |
356 |
440 |
286 |
325 |
346 |
357 |
|
RTRIA |
144 |
213 |
57 |
146 |
42 |
118 |
|
SMA |
154 |
229 |
215 |
77 |
71 |
155 |
|
Whole brain |
4949 |
5015 |
4698 |
5135 |
5062 |
4634 |
Table 2. Subject wise selected voxels
|
Subject |
Selected feature vectors |
|
04799 |
59, 188, 198, 316, 326, 370, 392, 426, 434, 449, 546, 553, 732, 855, 866, 944, 971, 1042, 1068, 1090, 1366, 1446, 1452, 1470, 1532, 1551, 1566, 1742, 1803, 2274, 2401, 2402, 2501, 2505, 2803, 2876, 2889, 2896, 2923, 2947, 2956, 3113, 3159, 3213, 3271, 3286, 3341, 3390, 3403, 3417, 3594, 3609, 3614, 3630, 3657, 3706, 3908, 4105, 4390, 4432, 4717, 4758 |
|
04820 |
291, 331, 348, 1156, 1361, 1369, 1476, 1542, 1571, 1609, 1692, 1722, 1873, 1925, 1932, 1933, 1934, 2000, 2075, 2239, 2422,2552,2892,2909, 3140, 3182, 3278, 3397, 3414, 3430, 3544, 3576, 3614, 3783, 3810, 3877, 4082, 4162, 4173, 4311, 4349, 4398, 4435, 4459, 4698, 4841 |
|
04847 |
67, 148, 202, 281, 342, 520, 917, 1205, 1307, 1440, 1453, 1566, 1604, 1616, 1660, 1740, 1917, 2034, 2088, 2226, 2891, 2984, 3114, 3340, 3545, 3645, 3713, 3716, 3881, 4030, 4180, 4380, 4385, 4412, 4547, 4582, 4684 |
|
05675 |
208, 221, 364, 438, 441, 456, 524, 758, 817, 859, 932, 950, 991, 1007, 1065, 1241, 1282, 1535, 1561, 1565, 1583, 1617, 1653, 1656, 1790, 1824, 1849, 1875, 2059, 2164, 2252, 2306, 2384, 2393, 2453, 2573, 2601, 2633, 2975, 3021, 3059, 3097, 3102, 3123, 3137, 3138, 3197, 3532, 3580, 3621, 3827, 3840, 3932, 4086, 4390, 4538, 4567, 4585,4696, 4845 |
|
05680 |
45, 123, 611, 786, 935, 939, 1051,1217, 1342, 1351, 1378, 1449, 1866, 1915, 1990, 2021, 2098, 2135, 2281, 2487, 2516, 2531, 2539, 2557, 2883, 2912, 2959, 3331, 3697, 3756, 3879, 4081, 4161, 4176, 4448, 4592, 4772, 4920, 5048, 5061 |
|
05710 |
35, 242, 344, 529, 598, 711, 751, 832, 847, 886, 1075, 1252, 1277, 1479, 1488, 1542, 1552, 1560, 1756, 1938, 2091, 2233, 2379, 2441, 2643, 2792, 2967, 3009, 3038, 3075, 3431, 3542, 3622, 3656, 3693, 3715, 3807, 3841, 4070, 4118, 4165, 4253, 4261, 4309 |
3.5 Feature selection
For classification, the feature which is highly correlated with the class and having minimal correlation with the other feature is selected considering correlation as goodness measure in feature selection [24]. This feature selection technique works in two steps- first the features are selected relevant to the class and second, iteratively eliminate other features based on the selected feature. Feature which is relevant to the class concept and not redundant to other relevant feature assumed to be good. Correlation measure based on information theoretical concept of entropy for variable x is given by
$H(X)=-\sum_{i=1}^{m} P\left(x_{i}\right) \log _{2}\left(P\left(x_{i}\right)\right)$ (3)
The range of i is from 1 to number of classes (M) The entropy of X after observing the variable Y is represented by
$H(X / Y)=-\sum_{j=1}^{N} P\left(y_{j}\right) \sum_{i=1}^{M} P\left(x_{i} / y_{j}\right) \log _{2}\left(P\left(x_{i} / y_{j}\right)\right)$ (4)
The range of j varies from 1 to N, where N is number of voxels(n).
Where, P(xi) are the prior probability for all values of X and $P\left(x_{i} / y_{i}\right)$ is the posterior probabilities of X given the values of Y. The information gain is the decrease in entropy of X provided by Y and is given by amount by
$I G(X / Y)=H(X)-H(X / Y)$ (5)
Correlation being biased in favour of features having more value symmetry becomes a measure of correlation between features. Symmetrical uncertainty is represented as
$S U(X, Y)=2\left[\frac{I G(X / Y)}{H(X)+H(Y)}\right]$ (6)
Taking symmetrical uncertainty as goodness measure, relevant features are selected. The range of SU lies between 0 and 1. After finding the values of SU for all features we have selected the top dominating voxels based on the threshold value of SU. For data set S containing N features and C classes, symmetrical uncertainty is denoted as SUic for correlation between Fi and class C.
Then
$\forall F_{i} \in S, 1 \leq i \leq N, S U_{i} \geq \delta,(\delta \rightarrow \text { threshold })$
The highly correlated features which are obtained by minimizing the redundancy are summed up in in Table 2. The procedure recursively eliminates the irrelevant feature from the fMRI data and selects only those which are correlated.
The region wise distribution of selected features in different bran regions is shown in the Table 3. Region-wise number of voxel selected in the determination of sentence classification from all six subjects when summed up category wise becomes -CALC(28), LDLPFC(24), LFEF(10), LIPL(21), LIPS(6), LIT(19), LOPER(5), LPPREC(7), LSGA(7), LSPL(11), LT(17), LTRIA(7), RDLPFC(19), RFEF(6), RIPL(19), RIPS(9), RIT(10), ROPER(8), RPPREC(2), RSGA(4), RSPL(16), RT(23), RTRIA(5), SMA(8).
Table 3. Region-wise distribution of selected feature
|
Area |
Sub1 |
Sub2 |
Sub 3 |
Sub 4 |
Sub 5 |
Sub 6 |
|
CALC |
8 |
4 |
4 |
8 |
2 |
2 |
|
LDLPFC |
3 |
5 |
1 |
5 |
5 |
5 |
|
LFEF |
3 |
3 |
1 |
0 |
1 |
2 |
|
LIPL |
3 |
1 |
2 |
10 |
5 |
0 |
|
LIPS |
2 |
0 |
0 |
3 |
0 |
1 |
|
LIT |
2 |
1 |
3 |
5 |
3 |
5 |
|
LOPER |
0 |
1 |
3 |
0 |
1 |
0 |
|
LPPREC |
0 |
2 |
0 |
1 |
1 |
3 |
|
LSGA |
1 |
1 |
2 |
2 |
0 |
1 |
|
LSPL |
2 |
2 |
2 |
1 |
3 |
1 |
|
LT |
3 |
3 |
2 |
2 |
3 |
4 |
|
LTRIA |
2 |
1 |
1 |
0 |
1 |
2 |
|
RDLPFC |
5 |
2 |
2 |
2 |
4 |
4 |
|
RFEF |
2 |
2 |
0 |
1 |
0 |
1 |
|
RIPL |
9 |
0 |
1 |
4 |
2 |
3 |
|
RIPS |
3 |
0 |
0 |
3 |
1 |
2 |
|
RIT |
4 |
1 |
1 |
2 |
0 |
2 |
|
ROPER |
1 |
1 |
2 |
2 |
2 |
0 |
|
RPPREC |
1 |
0 |
0 |
1 |
0 |
0 |
|
RSGA |
0 |
1 |
2 |
0 |
1 |
0 |
|
RSPL |
2 |
2 |
4 |
4 |
2 |
2 |
|
RT |
4 |
5 |
5 |
3 |
3 |
3 |
|
RTRIA |
0 |
5 |
0 |
0 |
0 |
0 |
|
SMA |
2 |
3 |
1 |
1 |
0 |
1 |
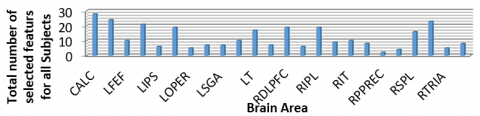
From this discussion it’s clear that the most contributing voxels comes from region CALC and LDLPFC. Figure 3 represents the total number of features selected from different region of brain for all subjects.
Figure 3. Region-wise total number of selected features from all subject
3.6 Classification using multilayer perceptron
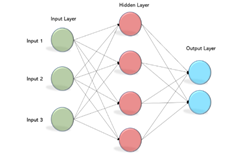
A multilayer perceptron (MLP) [25, 26] is a class of feed forward artificial neural network. MLP consists of at least three layers of nodes: an input layer, a hidden layer and an output layer. Figure 4 represents the architecture of MLP. Except for the input nodes, each node that uses a nonlinear activation function. MLP utilizes a supervised learning technique called back propagation [27] for training:
Figure 4. Multilayer perceptron
Single-hidden-layer MLP function can be seen as f: RD→RL, where the size of input vector x is D, and the size of the output vector f(x) is L,
The matrix notation is given as
$f(x)=G\left(b^{(2)}+W^{(2)}\left(s\left(b^{(1)}+W^{(1)} x\right)\right)\right)$ (7)
With b(1), b(2) are bias vectors; W(1), W(2) are weight matrices, and, G and s are activation functions.
The hidden layer is
$h(x)=\phi(x)=s\left(b^{(1)}+W^{(1)} x\right)$ (8)
where, $W^{(1)} \in R^{D * D_{h}}$ is the weight matrix connecting the input vector to the hidden layer. Each column Wi(1) represents the weights from the input units to the ith hidden unit.
The choice for S is given by
$\tanh (a)=\left(e^{a}-e^{-a}\right) /\left(e^{a}+e^{-a}\right)$ (9)
The output vector is then obtained as:
$o(x)=G\left(b^{(2)}+W^{(2)} h(x)\right)$ (10)
The selected feature vectors are fed to the classifier. The classifier is trained to classify the brain state in the processing of affirmative sentences and negative sentences with the assumption that- a) fMRI data has sufficient information to find out the state of the brain corresponding to specific sentence type b) Machine learning algorithm is well efficient to learn the particular temporal pattern to distinguish between the processing of negative vs. affirmative sentences. MLP classification technique is applied to classify the selected feature vectors. In this paper, gradient descent method is used for updating weights and bias during the training of the MLP. Bias nodes are added to increase the flexibility of the model to fit the data by allowing the activation function to be shifted to the left or right. At the beginning, network is initialised with small random weights and then gradient descent is used to tune the weighs into optimized values. Initially, the value of bias is set to 0 and later gradient descent optimizer is used to tune the bias. After the training the model can detect the brain state corresponding to affirmative or negative sentences.
The performance of a classifier is judged upon the number of wrongly classified instances, i.e., the error rate or misclassification. The goal of the classification model is the determination of its ability to correctly classifying or predicting the class of instances. The confusion matrix explores the error and correctly classified test data in terms of true positive, false positive, etc. The number of correct and incorrect predictions is displayed by the confusion matrix in Table 4. The column entries represent the predicted class value, and rows display the actual class values.
The metrics used in the study are given below-
•TP Rate stands for the rate of true positives, i.e., correctly classified instances as a given class.
•FP Rate means the rate of false positives, i.e., falsely classified instances as a given class.
•Precision: the proportion of instances that are true of a class divided by the total cases classified as that class
•Recall: the proportion of instances classified as a given class divided by the actual total in that class (equivalent to TP rate)
•F-Measure is the harmonic mean of recall and precision and defined as 2 * Precision * Recall / (Precision + Recall)
•MCC is used in machine learning as a measure of the quality of binary (two-class) classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes
•ROC (Receiver Operating Characteristics) area gives an idea of how the classifiers are performing in general.
The model is trained on the selected feature vector data set and tested on the ten-fold cross-validation approach. The accuracy of the result is good enough and can detect sentence polarity with more than 93% accuracy. Table 5 shows the subject wise accuracy result of the sentence polarity task. The average of overall performance analysis in the sentence polarity task is represented in Figure 5, where the performance metric is as following- TP Rate: 0.933333, FP Rate: 0.066667, Precision: 0.940167, Recall: 0.933333, F-Measure: 0.933, ROC Area: 0.980167, Accuracy: 0.933333. The result obtained is quite appreciable as the average classification accuracy of the brain state in the sentence polarity task is more than 93%.
Table 4. Confusion matrix
|
Subject id |
Predicted Class |
Actual Class |
|
|
Affirmative |
Negative |
||
|
04799 |
16 |
4 |
Affirmative |
|
0 |
20 |
Negative |
|
|
04820 |
19 |
1 |
Affirmative |
|
1 |
19 |
Negative |
|
|
04847 |
18 |
2 |
Affirmative |
|
0 |
20 |
Negative |
|
|
05675 |
19 |
1 |
Affirmative |
|
0 |
20 |
Negative |
|
|
05680 |
20 |
0 |
Affirmative |
|
4 |
16 |
Negative |
|
|
05710 |
18 |
2 |
Affirmative |
|
1 |
19 |
Negative |
|
3.7 Comparative analysis
Behroozi et al. [28] have classified the voxel from the RDLPFC area and achieved an accuracy of almost 75% for all the subjects on the same data set. They have used F-score based feature selection and SVM classification techniques in the classification of selected attributes. In our approach, we have scored more than 93% accuracy in polarity detection.
Doborjeh et al. [29] have studied the neural activity of affirmative and negative sentences and using NeuCube [30] on the same data set. With proper training after implementing classifiers to classify the neural activity pattern of negative and affirmative sentences in the brain, this model was able to recognize the sentence based on their polarity up to 90% accuracy.
From the above studies, it is clear that our result is evident and has much better classification accuracy than previous approaches. Comparing the classification accuracy of the proposed model with the above-mentioned approaches, the result obtained in the proposed model is significantly higher. Figure 6 shows the comparative analysis of the accuracy of the proposed model with the above-mentioned approaches.
This study is an attempt to recite the state of the brain based on fMRI data acquired when the subjects are indulged in reading two types of sentences i.e. affirmative or negative sentence. Brain processes affirmative and negative sentences differently and the activation produced in the brain is not alike for both types of sentences.
Table 5. The classification result
|
Subject |
TP Rate |
FP Rate |
Precision |
Recall |
F-Measure |
ROC Area |
Accuracy |
|
04799 |
0.90 |
0.1 |
0.917 |
0.9 |
0.899 |
0.993 |
0.900 |
|
04820 |
0.95 |
0.05 |
0.95 |
0.95 |
0.95 |
0.995 |
0.950 |
|
04847 |
0.95 |
0.05 |
0.955 |
0.95 |
0.95 |
0.963 |
0.950 |
|
05675 |
0.975 |
0.025 |
0.976 |
0.975 |
0.975 |
0.995 |
0.975 |
|
05680 |
0.9 |
0.1 |
0.917 |
0.9 |
0.899 |
0.95 |
0.900 |
|
05710 |
0.925 |
0.075 |
0.926 |
0.925 |
0.925 |
0.985 |
0.925 |
Figure 5. Average of results for all subjects
Figure 6. Comparative accuracies of recent works on the same data-set
The paper proposed a model of brain using filtered subset evaluator based feature selection and multilayer perceptron classification technique to classify the state of the brain based on fMRI data. fMRI data is extracted for sentence processing from Star Plus data-set. From extracted data mean is calculated to find out effective activation at all points of brain regions. Prominent features (voxels) are extracted using entopy based feature selection. Using MLP, cognitive state of the brain is decoded in sentential negation paradigm. The result shows that certain brain regions like LDLPFC and CALC are prominent areas for the classification of affirmative and negative sentences in brain, and RPPREC and RSGA are less contributing. This proposed model achieved 93.33% accuracy in sentence polarity detection tasks which is significantly encouraging than other methods on the same data-set.
|
t |
Time in second |
|
f |
function |
|
X,Y M |
features Number of Classes |
|
N |
Number of Voxels |
|
H |
Entropy |
|
i,j |
Indices |
|
$\delta$ |
Threshold |
|
x |
Input vector |
|
D |
Size of input vector |
|
L |
Size of output vector |
|
o(x) |
Output Vector |
|
b |
Bias |
|
W |
Weight Matrix |
|
G,s |
Activation function |
|
SU |
Symmetrical uncertainty |
|
IG |
Information Gain |
[1] Flöel, A., Buyx, A., Breitenstein, C., Lohmann, H., Knecht, S. (2005). Hemispheric lateralization of spatial attention in right-and left-hemispheric language dominance. Behavioural Brain Research, 158(2): 269-275. https://doi.org/10.1016/j.bbr.2004.09.016
[2] Costanzo, E.Y., Villarreal, M., Drucaroff, L.J., Ortiz-Villafañe, M., Castro, M.N., Goldschmidt, M., Camprodon, J.A. (2015). Hemispheric specialization in affective responses, cerebral dominance for language, and handedness: Lateralization of emotion, language, and dexterity. Behavioural Brain Research, 288: 11-19. https://doi.org/10.1016/j.bbr.2015.04.006
[3] Kaan, E., Swaab, T.Y. (2002). The brain circuitry of syntactic comprehension. Trends in Cognitive Sciences, 6(8): 350-356. https://doi.org/10.1016/s1364-6613(02)01947-2
[4] Fiveash, A., Thompson, W.F., Badcock, N.A., McArthur, G. (2018). Syntactic processing in music and language: Effects of interrupting auditory streams with alternating timbres. International Journal of Psychophysiology, 129: 31-40. https://doi.org/10.1016/j.ijpsycho.2018.05.003
[5] Yang, Y., Wang, J., Bailer, C., Cherkassky, V., Just, M.A. (2017). Commonality of neural representations of sentences across languages: Predicting brain activation during Portuguese sentence comprehension using an English-based model of brain function. NeuroImage, 146: 658-666. https://doi.org/10.1016/j.neuroimage.2016.10.029
[6] Feng, S., Qi, R., Yang, J., Yu, A., Yang, Y. (2020). Neural correlates for nouns and verbs in phrases during syntactic and semantic processing: An fMRI study. Journal of Neurolinguistics, 53: 100860. https://doi.org/10.1016/j.jneuroling.2019.100860
[7] Meyer, L., Friederici, A.D. (2016). Neural systems underlying the processing of complex sentences. Neurobiology of Language, 597-606. https://doi.org/10.1016/b978-0-12-407794-2.00048-1
[8] Rogalsky, C. (2016). The role of the anterior temporal lobe in sentence processing. Neurobiology of Language, 587-595. https://doi.org/10.1016/b978-0-12-407794-2.00047-x
[9] Friederici, A.D. (2011). The brain basis of language processing: From structure to function. Physiological Reviews, 91(4): 1357-1392. https://doi.org/10.1152/physrev.00006.2011
[10] Yokoyama, S., Maki, H., Hashimoto, Y., Toma, M., Kawashima, R. (2012). Mechanism of case processing in the brain: An fMRI study. PLoS One, 7(7): e40474. https://doi.org/10.1371/journal.pone.0040474
[11] Haegeman, L. (1995). The Syntax of Negation. Cambridge, Cambridge Univerisity Press. https://doi.org/10.1017/cbo9780511519727
[12] Mayo, R., Schul, Y., Burnstein, E. (2004). “I am not guilty” vs “I am innocent”: Successful negation may depend on the schema used for its encoding. Journal of Experimental Social Psychology, 40(4): 433-449. https://doi.org/10.1016/j.jesp.2003.07.008
[13] Zwaan, R.A. (2012). The experiential view of language comprehension: How is negation represented. Higher Level Language Processes in The Brain: Inference and Comprehension Processes, Erlbaum, 255-288.
[14] Carpenter, P.A., Just, M.A., Keller, T.A., Eddy, W.F., Thulborn, K.R. (1999). Time course of fMRI-activation in language and spatial networks during sentence comprehension. Neuroimage, 10(2): 216-224. https://doi.org/10.1006/nimg.1999.0465
[15] Hasegawa, M., Carpenter, P.A., Just, M.A. (2002). An fMRI study of bilingual sentence comprehension and workload. Neuroimage, 15(3): 647-660. https://doi.org/10.1006/nimg.2001.1001
[16] Tettamanti, M., Manenti, R., Della Rosa, P.A., Falini, A., Perani, D., Cappa, S.F., Moro, A. (2008). Negation in the brain: Modulating action representations. Neuroimage, 43(2): 358-367. https://doi.org/10.1016/j.neuroimage.2008.08.004
[17] Christensen, K.R. (2009). Negative and affirmative sentences increase activation in different areas in the brain. Journal of Neurolinguistics, 22(1): 1-17. https://doi.org/10.1016/j.jneuroling.2008.05.001
[18] Bahlmann, J., Mueller, J.L., Makuuchi, M., Friederici, A.D. (2011). Perisylvian functional connectivity during processing of sentential negation. Frontiers in Psychology, 2: 104. https://doi.org/10.3389/fpsyg.2011.00104
[19] Kumar, U., Padakannaya, P., Mishra, R.K., Khetrapal, C.L. (2013). Distinctive neural signatures for negative sentences in Hindi: An fMRI study. Brain Imaging and Behavior, 7(2): 91-101. https://doi.org/10.1007/s11682-012-9198-8
[20] http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-81/www/, accessed on 12 Jan. 2020.
[21] Pandey, P., Jha, B.K., Sinha, N. (2016). Analyzing cognitive states using fMRI data. Procesure Computer Science, 90: 35-41. https://doi.org/10.1016/j.procs.2016.07.007
[22] Wang, X., Mitchell, T. (2002). Detecting cognitive states using machine learning, 1-10.
[23] Eddy, W., Fitzgerald, M., Genovese, C., Lazar, N., Mockus, A., Welling, J. (1999). The challenge of functional magnetic resonance. Imaging. Journal of Computational and Graphical Statistics, 8(3): 545-558. https://doi.org/10.2307/1390875
[24] Dash, M., Liu, H. (1997). Feature selection for classification. Intelligent Data Analysis, 1(3): 131-156. https://doi.org/10.1016/s1088-467x(97)00008-5
[25] Ruck, D.W., Rogers, S.K., Kabrisky, M., Oxley, M.E., Suter, B.W. (1990). The multilayer perceptron as an approximation to a Bayes optimal discriminant function. IEEE Transactions on Neural Networks, 1(4): 296-298. https://doi.org/10.1109/72.80266
[26] http://deeplearning.net/tutorial/mlp.html, accessed on 12 Jan. 2020.
[27] https://becominghuman.ai/multi-layer-perceptron-mlp-models-on-real-world-banking-data-f6dd3d7e998f, accessed on 12 Jan. 2020.
[28] Behroozi, M., Daliri, M.R. (2015). RDLPFC area of the brain encodes sentence polarity: A study using fMRI. Brain Imaging and Behavior, 9(2): 178-189. https://doi.org/10.1007/s11682-014-9294-z
[29] Doborjeh, M.G., Capecci, E., Kasabov, N. (2014). Classification and segmentation of fMRI spatio-temporal brain data with a NeuCube evolving spiking neural network model. In 2014 IEEE Symposium on Evolving and Autonomous Learning Systems (EALS), Orlando, USA, pp. 73-80. https://doi.org/10.1109/eals.2014.7009506
[30] Kasabov, N.K. (2014). NeuCube: A spiking neural network architecture for mapping, learning and understanding of spatio-temporal brain data. Neural Networks, 52: 62-76. https://doi.org/10.1016/j.neunet.2014.01.006