Donald Mouafo* | Ulrich Biaou
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Recent progress in computer vision applied to facial analysis has led to state-of-the-art face detection and facial feature extraction models. A cautious implementation of these models into face recognition pipelines can enable achieving superior performances and popularized daily applications of face recognition in a variety of domains. However, modern face recognition system is a multi-steps process including face detection, feature extraction and classification model. Developing a high-performance face recognition application generalizing on local data set remains challenging. In this paper, we present Deep learning based face recognition system employing MTCNN for face detection and FaceNet for feature extraction. We compare KNN and SVM classification models trained on the facial features extracted from prepared labeled faces. Both models demonstrated almost 100% accuracy on static test faces. Moreover, as face pose get more pronounced, far above 30°, both SVM and KNN models demonstrate efficient recognition rate of 95.95% and 96.67% respectively. Real-time evaluation shows less than 1% deviation from the static performances with both classifiers on less 30° tilted images.
biometric, face detection, face recognition, SVM, KNN, control access, pose variation, FaceNet
The control access to physical or virtual restrictive zone is a well-known problem for which numerous of solutions exist such as stand-alone lock, digital or badge reader [1]. Hence, accessing a domain requires a physical key in case of traditional stand-alone lock, a password, or Personal Identification Number (PIN) in the case of digital reader lock and a card or badge in the case of badge readers [2]. Although, the security level provided by all these solutions differ from one to another, it remains globally limited. Indeed, physical key can be lost, stollen or duplicated [3]. The same as passwords and PINs which in addition are difficult to remember and can be guessed. Cards, tokens, and the like can in addition be misplaced, forgotten, or duplicated while magnetic cards can become corrupted and unclear [1, 4]. Furthermore, supporting the development of smart buildings requires adapted control access management systems capable of expanding its scope and usage.
In this context, biometric-based techniques have emerged as a most promising alternative for recognizing individuals and granting access to a specific zone. Authentication is conducted by comparing the biometric data of the applicant such as fingerprints, palm prints, face, or iris [5, 6] to the data base of known people. Fingerprint-based solutions require physical contact with the authentication equipment which is a significant constraint. In addition, changes in the fingerprint signature due to injuries or inaccurate fingerprint reading for people with very thin body fingerprint layer make authentication difficult [7]. Therefore, facial signature appears as the most efficient biometric data for developing authentication systems given that it is rarely subject to sudden changes. Moreover, authentication based on facial biometric data is contactless and adaptable in the sense that even if an applicant's facial signature changes due an accident or surgery, the solution can easily be adapted to this new reality.
In this paper, we present a face recognition (FR) system for control access to restrictive zone. We employed Multi-Task Convolutional Neural Network (MTCNN) [8] for face detection and FaceNet [9] for face embedding extraction. We developed K-Nearest Neighbor (KNN) and Support Vector Machine (SVM) classifiers which were trained on the generated embeddings and respectively achieved 99.34% and 100% accuracy on static test faces. Setting a threshold probability to 0.85 for KNN and 0.25 for SVM enabled achieving a real-time recognition rate of 0.988 and 0.983 on near frontal faces with 0.002 and 0.012 unknown classification. In relatively high pose variation, that is above 30° up to near 90° the real time testing showed bad recognition rates below 0.007 for KNN and 0.016 for SVM. The rest of the paper is organized as follows: In Section 2, we present rapid literature survey of related work on FR systems. In Section 3, we present the structure of the proposed solution together with the analytic method. In Section 4, we present model evaluation followed by the discussion. The paper ends with the conclusion.
Face detection. FR system is a multistep process including in general face detection, feature extraction and classification or verification. Despite the complexities related to each of these steps, enthusiastic research activities have enabled great progress during the recent years [10]. Different algorithms exist for face detection and localization in a photo [11]. This includes Viola-Jones detector or haar like cascade, the Histogram of oriented gradient (HOG) method, the Local binary pattern (LBP) analysis method and its Local Binary Pattern Histogram (LBPH) variant. Although these models are efficient for face detection, they do not necessarily integrate post-processing such as the alignment of the detected face. However, the shift of the localized face is likely to considerably deteriorate the performances of the subsequent recognition. Modern face detector based on Convolutional Neural Network have been proposed among which Multi-Task Convolutional Neural Network (MTCNN) [8] and RestNet [12]. MTCNN is a state-of-the-art model which jointly handles the detection and alignment and thus, is extremely relevant for developing real time FR systems with constant face pose variation.
Embedding generation. In general, face recognition or verification consists of comparing the representation vectors or embeddings of the detected faces using either similarity distance metrics or classification models to find the best matches. The process of converting a detected face consisting to an array of pixels to a representation vector is referred to as embedding generation. The pioneering FR research was reported the years 1960s by W. Bledsoe, H. C. Wolf and C. Bisson consisted to manual measurement of facial features such as the size of the mouth, nose, eyes, the distance between the two eyes etc. by means of measurement instruments [13]. It was until the 1990s that the first work on automatic face detection and recognition in an image was reported using the EigenFaces method [14] which is still widely used today. Since then, there were numerous of developments [10]. However, the low performances of the models combined with long execution time remained for a long time the main obstacle for concrete applications of FR systems. The emergence of high-performance computers and the availability of large data base of faces have favored the development of high-performance Deep Convolutional Neural Network (DCNN) models adapted for concrete applications of FR systems. These includes the DeepFace developed by Facebook [15] and FaceNet by google [9] which has shown state of the art face recognition performances.
FR system. A realistic FR recognition system combines pre-trained face detector and embedding generator together with an appropriated classifier. Hartanto and Adji [1] presented a FR system for attendance detection using Haar cascade algorithm for face detection and LBPH for feature extraction. The results were reported to highly depend on the resolution of the camera providing the input video stream, the distance of face to the camera and the illumination intensity. Damale and Pathak [5] employed RestNet caffe model for face detection and used Linear Discriminant Analysis (LDA) and PCA methods for feature extraction and finally the SVM model for classification. They alternatively implemented CNN based model trained for classification. On static images, they observed a maximum accuracy of 88% for SVM-PCA based model which increased to 98% when using CNN. However, on real time prediction the best reported performance was 57% for ML method and 89% for CNN. More recently, Cahyono et al. [7] developed a FR solution for employee attendance using MTCNN for face detection and FaceNet for embedding generation and finally SVM for classification and conducted a comparative study of FaceNet and OpenFace models [16]. On the data set consisting of 150 images of 15 employees, the OpenFace's recognition accuracy was limited to 93% while FaceNet showed 100% accuracy. They conducted real-time implementation with FaceNet and claimed similar results. Irbaz et al. [17] also presented a FR application for real time tracking of remote employee based on MTCNN-FaceNet-KNN architecture. They reported several non-detected faces in some angle-oriented face position.
The proposed FR system intends to control the access to restricted domain and updates the list of validated authorizations in real time. Figure 1 presents the structure of the solution. One distinguishes both training pipeline (in gray) and prediction pipeline (in blue). In the former pipeline, training images are processed and passed to the next step where faces are detected and cropped. The cropped faces are subsequently used as input to FaceNet where embeddings are generated and compressed and saved in the database. The compressed embeddings are subsequently imported to train and evaluate the classifier which after evaluation is binarized and saved for future call during the prediction. In the prediction pipeline, when an applicant approaches the door, the application processes the video stream from the control access camera. After face detection, it processes the applicant's detected face, makes prediction, and performs the authorization check and grants or not the access.
Figure 1. Structure of the FR system with training and prediction pipelines
3.1 Dataset
The dataset consists of pictures of colleagues completed with those of celebrities obtained from google images under permissive license. The composed dataset is then split into train and test sets. The train set consist of 371 images of faces with different orientations and evenly distributed into 15 classes. The test set contains 156 images with at least 5 images per class. To evaluate the performances of the system on face pose variations, we prepared a specifics test set of colleague images with different face poses comprising Frontal and (20°, 35°, 65°, 75°, 85°) horizontally tilted away from the camera. At each of these positions, we recorded three images per individual at approximately 0°, 40°, 65° upward orientation. We then twice augmented each set by adding gaussian noise to each recorded image. It finally resulted a data set consisting of six subsets corresponding to the above-mentioned horizontal positions each of which includes 6 images per colleagues.
3.2 Processing
Face detection consists of locating the position in an image of the bounding box (BB) containing the face. The coordinate of the BB then serves cropping the face from the original image. Prior to input into FaceNet for embedding extraction, the resulting face image is rescaled to fulfill input size requirement of (160x160) pixels and subsequently standardized following Eq. (1).
$\overline{\text { Plxel }}=($ Pixel $-\mu) / \delta$ (1)
where, $\overline{P_{\text {lxel }}}$ is the normalized value of each pixel of an image. μ and δ are respectively the average and the standard deviation of the array of pixels of the corresponding cropped face.
Figure 2. Structure of FaceNet model consisting of batch input layer, deep CNN architecture and L2 normalization resulting in the face embedding [9]
3.3 Feature extraction
The feature or embedding vector obtained belongs to and Euclidean space of the same dimension as the vector size. Hence, different distance algebra can apply to enable classification or clustering of faces based on their vector representation using machine learning methods such as KNN or SVM. Most of the previously mentioned DCNN based models generate embedding as output of an intermediate bottleneck layer. Instead, FaceNet optimizes the embedding itself thanks to a subtitle implementation of triplet loss function (Figure 2). Triplet loss function optimization consists of comparing embeddings of three face images which are the anchor (input images), the positive (face image of the same person as anchor) and the false (face image of a different person).
$\mathcal{L}=\sum_{i}^{N} \max \left\{\left\|A_{i}-P_{i}\right\|_{2}^{2}-\left\|A_{i}-N_{i}\right\|_{2}^{2}+\alpha, 0\right\}$ (2)
where, A and P the embeddings of the anchor, positive and negative images; α and N are respectively the margin imposed between positive and negative pairs and the total number of triplets. As highlighted in Figure 3, the purpose is to minimize the distance between an anchor and positive as they have same identity and maximize the distance between the anchor and the negative as they are of different identities. During model training, this process consists of minimizing the triplet loss function given by Eq. (2). Doing so, FaceNet demonstrated state-of-the-art performances using face representation vector size of 128 as compared to other models and is wildly used today in FR systems.
Figure 3. The Triplet Loss function: Method of distance minimization between image of the same identity (an anchor and a positive) and maximization between images of different identities (the anchor and a negative)
3.4 Classification
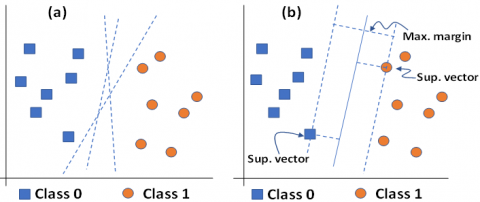
To compare and benefit from the most efficient, we tested both KNN and SVM for classification as they are widely used in face recognition [10]. The SVM’s principle consists of defining a hyperplane that best separates different classes of the data. In the simple case of binary classification (Figure 4), this is done by computing the distance between hyperplane candidates and the nearest data points from either side known as support vectors (Figure 4 (a)). The goal is to find the hyperplane that represents the maximum distance or margin between the two classes (Figure 4 (b)). When the data are not linearly separable, SVM allows using kernel function to map the original feature vectors into a higher dimensional space where optimal hyperplane is presumably much easier to obtain [18]. Various kernel functions exist and offer the adaptability of SVM to a variety of learning complexities.
Figure 4. SVM’s principle for finding the optimal hyperplane. (a) Different possible separation boundaries between classes. (b) The optimal choice resulting to the largest margin between classes
KNN classification is a supervised machine learning algorithm that stores the training features and classifies new features based on the similarity measures. The similarity measure consists, for a given new features, to evaluate the distance metric to its neighbors and assign the corresponding class after majority voting on the nearest neighbor classes. Though, Euclidean distance is the commonly used distance metric, KNN offers alternative with Manhattan, Minkowski and other distance metrics.
Figure 5. Image processing prior to face recognition. Original image (a). Face detection illustrated by the green bb (b) (c) Cropped face based on bb. Cropped face resized to (160x160) pixels (d)
The performances of the proposed face recognition system are evaluated using the data set described in section 3.1. Figure 5 illustrates the processing caried out prior to embedding extraction and classification. Indeed, the original RGB image (Figure 5 (a)) is input to MTCNN to proceed face detection. The detection is illustrated by the green BB in Figure 5 (b). The detected face in then cropped (Figure 5 (c)) in perspective to be used as input to the embedding generation model. However, as FaceNet required (160x160) pixels input size, the cropped face is resized consequently. Subsequently, the face image is normalized (Eq. (1)) and passed as input to FaceNet to proceed feature extraction, that is, the input face image is converted into 128-dimensional facial feature vector representation (embedding). In the training pipeline, these processes of detection and feature extraction are carried out for all images in the train set. The system is subsequently evaluated on the test set.
Figure 6. Visualization of face embeddings in 2-dimensional space. (a) Train set. (b) Test set. The classes names are anonymized for representation purpose. The reduction into 2d space was conducted using Tsnet
Figure 6 presents the visualization of 128-dimensional facial features into 2-dimensional space for both train (Figure 6 (a)) and test faces (Figure 6 (b)). This visualization shows that identity clusters are well separated. This illustrates the efficiency of FaceNet in separating the identities of different classes. It worth mentioning that the test set images are prepared similarly as the train set prior to conduct prediction with the pretrained MTCNN and FaceNet models. The labeled train embeddings are then individually normalized to Euclidean unity vector before to be used to train the SVM and KNN classifiers.
4.1 Static evaluation
The Figure 7 presents the confusion metrices recorded on the test set for both SVM (top panel) and KNN (bottom panel) classifiers. SVM achieves maximum prediction accuracy on all classes while KNN demonstrates a single misclassification. It worth mentioning that the 15 class labels were intentionally anonymized from 0 to 14. It is to be notice that no threshold prediction probability was implemented when realizing static evaluation of the system. On average, both SVM and KNN demonstrate respective accuracy of 100% and 99.35%. Figure 8 illustrates the prediction of the KNN based system on two static images with different ethnicities. The pronounced orientation of the example images foreshadows the performances of our system on highly tilted images.
Table 1. Accuracy on tilted test set for KNN (SVM) Classifiers. The ‘-’ sign indicates the removal of the corresponding upward tilted faces
|
|
All set |
- 65° upward |
- (65°, 40°) upward |
|
0° |
1.0 (1.0) |
1.0 (1.0) |
1.0 (1.0) |
|
20° |
1.0 (1.0) |
1.0 (1.0) |
1.0 (1.0) |
|
30° |
1.0 (1.0) |
1.0 (1.0) |
1.0 (1.0) |
|
50° |
1.0 (1.0) |
1.0 (1.0) |
1.0 (1.0) |
|
70° |
0.93 (0.93) |
1.0 (1.0) |
1.0 (1.0) |
|
80° |
0.80 (0.87) |
0.85 (1.0) |
1.0 (1.0) |
This is in accordance with pretrained FaceNet model which implicitly implemented appropriate invariances to pose, illumination, and other variational conditions using a large dataset of labelled faces rather than using engineered features. Indeed, we evaluated our system with the dataset of tilted faces and the results are summarized in Table 1.
Interestingly, we obtained high performances that are preserved even for 70° and 80° horizontally tilted sets with accuracies of 93.33% (93.33%) and 80.00% (86.67%) respectively for KNN (SVM) models. As shown in Table 1 and confirmed by confusion matrix analysis, the reduction of accuracy at both horizontal orientations are due the additional 40° and 65° upward or vertically titled faces. Removing the corresponding faces increased the accuracy of the system to its maximum (see Table 1). This high prediction rate of the system on highly tilted pose images are not only favoured by the invariance of FaceNet to different pose images but was also boosted by including in our train set images of different pose orientations.
Figure 7. Confusion matrixes of both SVM (top panel) and KNN (bottom panel) models
Figure 8. Illustration of predictions made by the system from the celebrity Serena William and the famous mathematician Cédric Villani
4.2 Real time evaluation
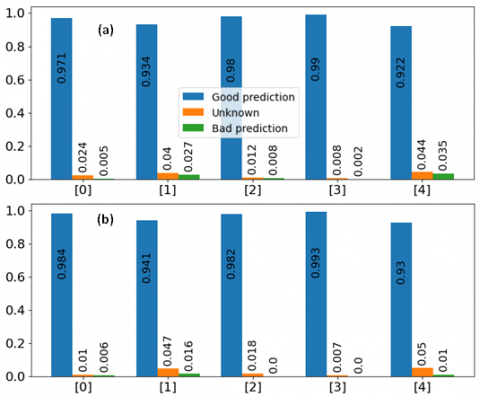
The system was tested by 5 colleagues in real time condition. Prior to deployed the system for testing, we implemented a module recording all the predictions and compare to the real identity of the tester. We set the threshold probabilities to 0.25 and 0.85 for SVM and KNN respectively. Below this threshold, the prediction class is automatically set to “unknown”. Thus, we reduced the evaluation for each tester to three classes problem namely “Good prediction”, “Unknown” and “Bad prediction”. In this context, the “Good prediction” class indicates the prediction corresponding to the tester while the latter “Bad prediction” class indicates all predictions different from the two former classes. It represents, for the control access usage the effective wrong prediction i.e., the worst case where a person can access a zone while he is not allowed to. The Figure 8 presents the bar plot of the statistic average of three class predictions after the real time test by the 5 colleagues. The recommendation to the colleague was to remain approximately bellow 30° face pose from the camera in other stay close to frontal face condition which we believe could be the average condition of control access. One observes an average prediction accuracy of 98.78% and 98.28% for KNN and SVM respectively. Interestingly, the prediction rate of the “Bad prediction” class remains extremely marginal as well as the “Unknown” class. This is comforting as it implies that it will be extremely rare for the system to let in a person who is not allow to. The five test classes are intentionally anonymized from [0] to [4].
Figure 9. Statistics of real time evaluation of the system by 5 colleagues. (a) KNN classifier. (b) SVM classifier
Further, we evaluated the performances of the system in condition where the control or surveillance could be made for security purpose based on the video flux from security camera. In contrast to control access where recognition is often based on frontal images, the need in this case is the capability of recognition of the system in condition of highly tilted images. The purpose is to check if the capability of the system on highly tilted static images remains preserved in real time given that the fluctuation of illumination and the video quality are known to deteriorate the accuracy. The statistics of prediction by the system on the five colleagues facing different directions from approximately above 30° up to 85° tilted angles either horizontally or vertically are presented in Figure 10. For both classifiers the average good prediction rate of 0.92 and 0.86 respectively for SVM and KNN is very satisfactory given the testing conditions. More interestingly, based on the threshold probabilities settings, the effective average wrong prediction rate is limited to 0.02. This highlights the robustness of the systems in the situation of highly tilted faces.
Figure 10. Statistics of the system’s predictions in up to 85° tilted face pose conditions. (a) SVM based system. (c) KNN based system
Illumination is a well kwon problem for developing efficient real time FR solution [19]. The real time evaluation of the system was conducted in door under normal artificial light which in principle is susceptible of limited illumination variation. However, as the light source is fixed, constant pose change induces non negligeable illumination fluctuation that the pretrained FaceNet model is in principle able to handle. Nevertheless, comparatively to European ethnicity the system has demonstrates more difficulty on people of same ethnicity as in Figure 5 particularly in situation where they were not facing the artificial light. Indeed, most of the misclassifications implying the classes [7, 8] in Figure 8 (a) and classes [1, 4] in Figures 9 and 10 are due to this fact. The reason for the system to show less efficiency to people of darker skin color ethnicity is related to the low contrast at similar illumination level compared to other classes. Obviously, better illumination condition can enable overcoming this problem. However, in other to minimize this problem and provides robustness to the model achieving the result presented in this paper, we implement contrast improvement prior to features extraction using Contrast Limited Adaptive Histogram Equalization (CLAHE) [19, 20] during real time prediction. We optimized the threshold to find best balance between optimizing the contrast of darker images and keeping the condition of optimal contrast for other images or frame.
The adaptability of Face recognition systems offers a verity of possibilities in various domains including the access management and security of smart buildings. In our research, we presented a practical approach of FR for control access to restrictive domain using MTCNN and FaceNet models. The proposed FR system enables achieving 100% and 99.35% on static data set based respectively on SVM and KNN. Real time implementation demonstrates very good prediction rate with extremely marginal of bad predictions. Overall, the experiment demonstrates an efficient control access system to restrictive zone to authorized people without human intervention. It enables overcoming the limitation related to standard control access solutions such as digital code, magnetic card, and badge. More interestingly, it is flexible to camera position and remain efficient in tilted view angles and does not require any special hardware for its implementation.
|
CNN |
Convolutional Neural Network |
|
DCNN |
Deep Convolutional Neural Network |
|
KNN |
K-Nearest Neighbor |
|
SVM |
Support Vector Machine |
|
PCA |
Principal Component Analysis |
|
CLAHE |
Contrast Limited Adaptive Histogram Equalization |
|
MTCNN |
Multi-task Convolution Neural Network |
|
HOG |
Histogram of oriented gradient method |
|
LBP |
Local binary pattern (LBP) |
|
LBPH |
Local Binary Pattern Histogram |
[1] Hartanto, R., Adji, M.N. (2018). Face recognition for attendance system detection. In 2018 10th International Conference on Information Technology and Electrical Engineering (ICITEE), pp. 376-381. https://doi.org/10.1109/ICITEED.2018.8534942
[2] Jirjees, S.W., Nasser, A.R., Mahmood, A.M. (2021). RoundPIN: Shoulder surfing resistance for pin entry with randomize keypad. International Journal of Safety and Security Engineering, 11(6): 697-702. https://doi.org/10.18280/ijsse.110610
[3] Shavetov, S., Sivtsov, V. (2020). Access control system based on face recognition. In 2020 7th International Conference on Control, Decision and Information Technologies (CoDIT), 1: 952-956. https://doi.org/10.1109/CoDIT49905.2020.9263894
[4] Jafri, R., Arabnia, H.R. (2009). A survey of face recognition techniques. Journal of Information Processing Systems, 5(2): 41-68. https://doi.org/10.3745/JIPS.2009.5.2.041
[5] Damale, R.C., Pathak, B.V. (2018). Face recognition based attendance system using machine learning algorithms. In 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), pp. 414-419. https://doi.org/10.1109/ICCONS.2018.8662938
[6] Herbadji, A., Guermat, N., Ziet, L., Akhtar, Z., Cheniti, M., Herbadji, D. (2020). Contactless multi-biometric system using fingerprint and palmprint selfies. Traitement du Signal, 37(6): 889-897. https://doi.org/10.18280/ts.370602
[7] Cahyono, F., Wirawan, W., Rachmadi, R.F. (2020). Face recognition system using FaceNet algorithm for employee presence. In 2020 4th International Conference on Vocational Education and Training (ICOVET), pp. 57-62. https://doi.org/10.1109/ICOVET50258.2020.9229888
[8] Zhang, K., Zhang, Z., Li, Z., Qiao, Y. (2016). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10): 1499-1503. https://doi.org/10.1109/LSP.2016.2603342
[9] Schroff, F., Kalenichenko, D., Philbin, J. (2015). FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815-823. https://doi.org/10.1109/CVPR.2015.7298682
[10] Kortli, Y., Jridi, M., Al Falou, A., Atri, M. (2020). Face recognition systems: A survey. Sensors, 20(2): 342. https://doi.org/10.3390/s20020342
[11] Adouani, A., Henia, W.M.B., Lachiri, Z. (2019). Comparison of Haar-like, HOG and LBP approaches for face detection in video sequences. In 2019 16th International Multi-Conference on Systems, Signals & Devices (SSD), pp. 266-271. https://doi.org/10.1109/SSD.2019.8893214
[12] He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778.
[13] de Leeuw, K.M.M., Bergstra, J. (2007). The History of Information Security: A Comprehensive Handbook. (Chap. 10, pp. 264). Amsterdam: Elsevier.
[14] Turk, M., Pentland, A. (1991). Eigenfaces for recognition. Journal of Cognitive Neuroscience, 3(1): 71-86. https://doi.org/10.1162/jocn.1991.3.1.71
[15] Taigman, Y., Yang, M., Ranzato, M.A., Wolf, L. (2014). Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1701-1708. https://doi.org/10.1109/CVPR.2014.220.
[16] Baltrusaitis, T., Zadeh, A., Lim, Y.C., Morency, L.P. (2018). Openface 2.0: Facial behavior analysis toolkit. In 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pp. 59-66. https://doi.org/10.1109/FG.2018.00019
[17] Irbaz, M.S., Nasim, A., Abdullah, M.D., Ferdous, R.E. (2022). Real-time face recognition system for remote employee tracking. In Proceedings of the International Conference on Big Data, IoT, and Machine Learning, pp. 153-163. https://doi.org/10.1007/978-981-16-6636-0_13
[18] Parveen, P., Thuraisingham, B. (2006). Face recognition using multiple classifiers. In 2006 18th IEEE International Conference on Tools with Artificial Intelligence (ICTAI'06), pp. 179-186. https://doi.org/10.1109/ICTAI.2006.59
[19] Bendjillali, R.I., Beladgham, M., Merit, K., Taleb-Ahmed, A. (2020). Illumination-robust face recognition based on deep convolutional neural networks architectures. Indonesian Journal of Electrical Engineering and Computer Science, 18(2): 1015-1027. https://doi.org/10.11591/ijeecs.v18.i2.pp1015-1027
[20] Musa, P., Al Rafi, F., Lamsani, M. (2018). A review: Contrast-limited adaptive histogram equalization (CLAHE) methods to help the application of face recognition. In 2018 Third International Conference on Informatics and Computing (ICIC), pp. 1-6. https://doi.org/10.1109/IAC.2018.8780492