Manli Lv | Jianping Zhao* | Shengxian Cao| Zhenhao Tang
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The objective of this study was to obtain NOx emission prediction model at the inlet selective catalytic reduction (SCR) reactors, which was the basis of combustion optimization and denitrification treatment. A deep extreme learning machine (DELM) optimized by the sparrow optimization algorithm (SSA) was adopted to establish the NOx model based on data fusion of Computational Fluid Dynamics (CFD) simulation and Distributed Control System (DCD). The mechanism analysis and XGBoost algorithm was used to select input variables. The results show that the XGBoost-SSA-DELM-based prediction model has high prediction accuracy with mean absolute error of 2.54 mg/m3. The results of this study have important implications for research on improving combustion efficiency and reducing pollutant emissions.
NOx emission, deep extreme learning machine, CFD simulation, sparrow search algorithm
The excessive emission of nitrogen oxide (NOx) has seriously damaged the ecological and living environment and affected the human health. Thermal power plants are one of the main sources of NOx emissions. Despite clean sources of energy is rapidly developed, more than 70% of China's current electricity comes from coal-fired power plants in 2021. Currently, there are two main ways to reduce NOx emissions from coal-fired power plants, one is low nitrogen combustion in the furnace, and the other is denitrification of the furnace outlet. Due to the increasingly stringent emission restrictions, the NOx emission concentration after denitrification is generally required to be below 50 mg/m3 [1]. The NOx concentration at the inlet of the denitrification is in the range of 150 mg/m3 to 400 mg/Nm3. Modeling the NOx concentration at the inlet of the denitrification is of theoretical and practical significance because it can provide a model basis for the setting of combustion process control parameters and the optimal control of ammonia injection in denitrification process.
At present, in addition to the direct measurement of NOx emissions by Continuous Emission Monitoring System (CEMS), there are two indirect methods to obtain NOx concentrations, one is the mechanical method based on Computational Fluid Dynamics (CFD) simulation, and the other is the data-driven modeling method. In CFD simulation, the nonlinear mass, energy, component, and momentum differential equations of combustion process are solved and combustion state and the three-dimensional distribution of various combustion products can be obtained. Not only average NOx concentration value in a certain boiler crosssection but also its complete distribution.
Choi and Kim [2] investigated the formation of NOx in a 500MWe tangentially fired boiler using CFD simulation and thus provided a useful basis for the reduction and control of NOx. Ti et al. [3] simulated a 600-MWe boiler with two levels of OFA (over-fire air) technology and analyzed the effect of blade angle variation on NOx emissions. Some CFD simulation were carried out and investigated the influencing factors of NOx formation, such as the effect of air-staged combustion [4], excess air coefficient [5], burner tilt angle [6], SOFA distribution modes [7], swirl arrangement and coal injection mode [8]. Chang et al. [9] established a CFD model including flow, coal combustion and NOx formation for a 630MW tangentially fired pulverized-coal boiler under variable/low load conditions, aiming at solving the problem of decreasing combustion stability and increasing NOx emission in low-load operation. The study results gave the optimal burner tilt angle and burner arrangement mode of this unit. CFD simulation is an off-line modeling method and has a relatively long modeling time, so it is not suitable for real-time NOx prediction. The combustion process in power station is a complex physicochemical process, in which the complex mechanisms are difficult to be expressed by accurate reaction equations.
The other NOx emission prediction is based on data-driven method. With the development of computer technology and machine learning, the data driven methods provide a new way for model construction of NOx emission. Many NOx emission prediction modes have been developed based on the artificial neural network (ANN) [10]. Support Vector Machine (SVR) and least square support vector machine (LSSVM) had also been applied to predict the NOx emission [11]. The ELM algorithm was proposed by Huang in 2006 and successfully mapped the relationship between the operational parameters and NOx emission [12]. Currently, deep learning is undoubtedly become the biggest hotspot in the field of machine learning. The LSTM algorithm had been widely used to established NOx prediction in recent years [13]. Wang et al. [14] carried out three deep belief network (DBN)-based NOx emission prediction models for coal-fired power plants to verify the effectiveness of the deep learning algorithms. Wang et al. [15] proposed an ensemble DBN model based on random subspace for NOx concentration prediction, which has better prediction performance and generalization ability. To solve the difficulty of deep learning model parameter tuning, various optimization algorithms have been applied in the process of NOx modeling process such as particle swarm optimization [16], ant colony optimization [17], JAYA optimization [18], genetic algorithm [19] and Bayesian optimization [20].
The data-driven method can map the relationships between the input variables and NOx emission. The data sets for data-driven modeling of NOx concentration usually comes from distributed control system (DCS)operational data. In order to cover a larger range of variables, the latest studies have fused the CFD simulation data with DCS data to diversify the data and improve the generalization capability of the model [14, 20, 21].
In this study, a NOx emission prediction model based on a deep extreme learning machine (DELM) is proposed. Firstly, the corresponding experimental data are obtained by actual power plant DCS system and CFD simulation. Secondly, in order to reduce the model complexity, several variables that may affect NOx emissions are selected based on empirical and mechanistic analysis, and the XGBoost feature selection algorithm is used to determine optimal input parameter. Then, the DELM algorithm is used to conduct modeling research on NOx emissions, and sparrow search algorithm (SSA) algorithm is developed to automatically optimize the hyperparameters of the DELM model. In order to verify the validity of the model, relevant experiments were designed and compared with common modeling methods.
The rest of the paper is organized as follows. Section 2 described the study object and the process of training data set acquisition. The NOx formation mechanism and the variables selection introduced in Section 3. Section 4 proposes a DELM modeling method based on SSA hyperparameter optimization. The experimental results and corresponding discussion and analysis were given in section 5. Finally, the conclusion was drawn in Section 6.
2.1 Boiler description and DCS data acquisition
Figure 1. The schematic diagram of the 350 MW boiler
The object of this study is a 350MW supercritical boiler, which has a single furnace, π type layout, double flue at the end and balanced ventilation. The detailed schematic diagram of the boiler is shown in Figure 1. The boiler is 57.30 m in height and has a cross-section of 14.6273 m × 14.6273 m. Six layers of tiltable fuel-air nozzles (A, B, C, D, E, F) are installed on the four walls of the water cooled wall. Pulverized coal is blown into the furnace through six medium-speed coal mills. Eight layers of secondary air nozzles (AA, AB, BC, CC, DD, DE, EF, FF) locate at the four corners of the furnace. Fuel-air nozzles and secondary air nozzles are arranged alternately and symmetrically and formed two main combustion areas (upper combustion area and lower combustion area). Four layers of separate over-fire air (SOFA1~SOFA4) are located at the four corners of furnace over the main burner area. The new tangential fired mode has the advantages of short flame travel and good gas replenishment conditions on both sides of the flame.
The modeling data is taken from the power plant DCS. In order to improve the adaptability of model, the samples should cover as large a range of load variations and as many operating conditions as possible. The unit load varied from148.59MW to 352.84MW and NOx generating concentration of SCR inlet changed from 107.24 mg/m3 to 238.23mg/m3. 2000 operating data samples were collected with interval of 60 seconds by removing the unstable operating points from 5000 groups of historical operating data.
2.2 CFD simulation
(a) Global geometric model
(b) Refined mesh of furnace burner area
Figure 2. Geometric model and local refined mesh of boiler
Model prediction performance of the NOx emissions depends on the selection of training samples and modeling algorithms. In this paper, CFD simulation data is fused with DCS operation data to achieve sample diversification. CFD is a mechanism-based modeling method, which can off-line calculate the combustion state and the spatial distribution of pollutants in the furnace under any operating conditions. Figure 2 shows that the geometric model and mesh generation of CFD simulation. After the performed grid independence test, a grid with 2.8 million meshes was selected to simulate the combustion process. The combustion process was simulated in Fluent 15.0 software. The coal quality is considered to be constant during the simulation, and the boundary conditions and the mathematical model was described by in Lv et al. [22].
Since the boiler adopts the air-staged combustion method, the change of air distribution mode and tilting angle of dampers will affect the final combustion condition in the furnace and the final NOx emission. CFD simulation was carried out at 100%, 75% and 50% of the load to change the mill operation mode, the secondary air and SOFA distribution mode and the dampers tilting angle, etc. A total of 162 groups of samples were obtained. The NOx emissions were obtained by calculating the average NOx values in the cross-sectional area at the outlet of the economizer.
2.3 Framework of the proposed method
Establishing the NOx emission model in the furnace mainly consists of three steps, including data acquiring and processing, feature selection, parameter optimization and NOx modeling. The overall modeling process is described as in Figure 3.
Figure 3. Modeling framework of the NOx concentration based on DELM
Step1: According to the model requirements, training samples are extracted from the historical DCS data and combined with the data obtained from CFD simulations to form the training sample set.
Step2: Based on the simplified NOx formation mechanism, the initial variables are preselected. Then the XGBoost algorithm is used to feature select the initially selected variables, and the variables with high correlation coefficient with NOx emission concentration are selected as the optimal inputs to the model.
Step3: The DELM is used to establish the NOx concentration prediction model, and model parameters are optimized by the sparrow optimization algorithm.
Factors that affect the accuracy of data-driven modeling include the choice of algorithm, the training dataset, and the selection of input variables. Insufficient input variables will lead to inaccurate prediction, but too much input will increase computational complexity. In this paper, mechanism analysis and XGBoost feature selection are combined to select input variables for NOx emission modeling.
3.1 Input candidates for model
The formation and suppression of NOx in coal-fired boilers is a complex process, the NOx in the combustion process mainly includes fuel NOx and thermal NOx. Thermal NOx refers to the nitrogen oxide generated by oxidation of the atmospheric N2 in the combustion air at high temperature. The formation of thermal NOx is analyzed based on the extended Zeldovich mechanism. The principal reactions governing the formation of thermal NOX from molecular nitrogen are as follows:
$O+N_2 \Leftrightarrow N O+N$ (1)
$O+O_2 \Leftrightarrow N O+O$ (2)
$N+O H \Leftrightarrow N O+H$ (3)
It can be seen that the formation of thermal NO is mainly affected by oxygen distribution and furnace temperature.
Fuel NOx is produced by oxidation of molecular nitrogen present in the coal. The simple model is generally agreed by different researchers in Figure 4:
Figure 4. The simple models of fuel NOx
According to De Soete mechanism, the generation of fuel NOx is closely related to the pyrolysis product of coal and the oxygen concentration in the flame, so the formation of fuel NO is mainly affected by O2 concentration, type of fuel and char surface density.
Therefore, twenty-six variables were preselected as the input candidates for model, which contains unit load (x1), Coal feed rate (x2-x7), Secondary airflow (x8-x15), SOFA (x16-x19), total air volume (x20), total Coal rate (x21), secondary air temperature (x22), total secondary air volume (x23), Oxygen concentration (x24), furnace exit gas temperature (x25), tail flue gas temperature (x26).
3.2 Feature selection based on XGBoost
XGBoost is a boosted-tree-based machine learning system that contains a set of collection of iterative residual trees. Each tree learns the residuals of the previous N-1 trees and obtains the final predicted value of the sample by adding the new sample output values predicted by each tree. XGBoost expands the loss function according to the second-order derivative of Taylor's formula. By using both the first and second derivatives, XGBoost has faster convergence and higher accuracy [23].
To extract the best features for NOx data, this paper uses the XGBoost-based feature selection method. XGBoost feature selection depends on the importance of each feature's contribution to the model, and the importance is the sum of the number of times the feature is used for tree segmentation. Each segmentation of the tree in XGBoost takes a greedy approach to feature selection. The feature with the maximum current information gain is selected for tree segmentation. Information gain is calculated as shown in Eq. (4).
gain $=\frac{1}{2}\left[\frac{g_L^2}{h_L^2+\lambda}+\frac{g_R^2}{h_R^2+\lambda}-\frac{\left(g_L+g_R\right)^2}{\left(h_L+h_R\right)^2+\lambda}\right]-\gamma$ (4)
γ is the difficulty factor of the tabular tree partitioning, which is used to control the generation of the tree. λ denotes the L2 regularity factor. hi is the second-order derivative of the loss function, gi is the first-order derivative of the loss function, and the subscripts L and R represent the left and right subtrees.
After XGBoost modeling, the importance of NOx data features can be calculated and the importance of each feature is ranked from highest to lowest. The first dimension feature was modeled and the accuracy was calculated, and then gradually increase the dimensions used for modeling and record the accuracy rate. The dimension with the highest accuracy rate is the dimension for XGBoost feature selection.
The magnitude problem of the original data will affect the result of feature selection and the accuracy of subsequent modeling, so the original data is normalized and mapped to the space of [0,1] using Min-Max normalization.
According to the theory of data statistics, when the correlation coefficients is greater than 0.4, the variables have moderate or strong correlation. According to the XGBoost-based feature selection, except tail flue gas temperature (x26), 25 variables are retained as input variables to predict the NOx concentration at the SCR inlet.
4.1 DELM model
Deep extreme learning machine (DELM) is a deep network structure which is superimposed by multiple ELM Auto-Encoder (ELMA-AE). Its structure is shown in Figure 5. In this method, ELM-AE is initially used as the basic unit for unsupervised learning to train and learn the input data. When the input equals to the output, the coding vector of the hidden layer becomes the feature representation of the input. The algorithm steps of ELM-AE are as follows:
Step1: Randomly generate the input weights ω and bias b, and orthogonalize them.
Step2: Calculate the output of the hidden layer node:
$H=g(W X+b)$ (5)
Step3: Calculate the output weight β according to Eq. (6).
$\beta=\left\{\begin{array}{l}\left(\frac{1}{c}+H^T H\right) H^T X, N \leqslant n \\ H^T\left(\frac{1}{c}+H^T H\right) H^T X, N>n\end{array}\right.$ (6)
where, C is the network regularization parameter, which is introduced to improve the generalization performance of the ELM-AE method; x is the input sample matrix; n is the number of neurons in the hidden layer; N is the number of input samples, and g(i) the activation function. By training ELM-AE, unsupervised mapping of samples to depth features is realized.
DELM is built on the principle that the output weights of ELM-AE can map the learned features back to the input data, and the transpositions of the output weights can map the input data to the features. DELM is formed by stacking multiple layers of ELM-AE, and the input weights of hidden node of each layer are the transpositions of the output weights between that layer and the previous layer of ELM-AE, so that each layer is realized to abstractly extract the features of the previous layer, and this method is expressed as:
$H^k=g\left(\beta^k\right)^T H^{k-1}, k>1$ (7)
Figure 5. Schematic diagram of DELM
Different from other deep learning methods, DELM does not require fine-tuning. both the ELM-AE and the final DELM regression layers use least squares methods and only one-step inverse computation to obtain updated weights. Therefore, DELM has a fast training speed and is a suitable model for online modeling and real-time prediction of NOx emission.
4.2 Sparrow search algorithm (SSA)
Sparrow search algorithm(SSA) is a novel population intelligence optimization algorithm which is proposed in 2019 by Xue et al. [24]. In the SSA algorithm, the sparrows in the population are usually divided into producer and scrounger, and their identity is dynamically changing. Each sparrow will be given an initial position and a fitness degree determined by the fitness function, the magnitude of the fitness value indicates the strength of the discoverer's ability to search for food. and the producer's position is updated during the iteration as follows:
$X_{i, j}^{t+1}= \begin{cases}X_{i, j}^t \cdot \exp \left(\frac{-i}{\alpha \cdot \text { iter }_{\max }}\right) & \text { if } R_2<S T \\ X_{i, j}^t+Q \cdot L & \text { if } R_2 \geqslant S T\end{cases}$ (8)
where, t indicates the current iteration, j represent dimension. represents the value of the jth dimension represent dimensions of the ith sparrow at iteration t. itermax is a constant which indicates the maximum number of iteration. α $\in$ (0,1] is a random number. R2 represents the alarm value (R2 $\in$ [0,1]) and ST(ST $\in$ [0.5,1.0]) is the safety threshold respectively. Q is a random number which obeys normal distribution. L shows a matrix of 1×d for which each element inside is 1. When R2<ST, which means that there are no predators around, the producer enters the wide search mode. If R2≥ST, it means that some sparrows have discovered the predator, and all sparrows need quickly fly to other safe areas.
As for the scroungers, they need to enforce the rules (9) and (10). As mentioned above, some scroungers monitor the producers more frequently. Once they find that the producer has found good food, they immediately leave their current position to compete for food. If they win, they can get the food of the producer immediately, otherwise they continue to execute the rules (10). The position update equation for the scrounger is described as follows:
$X_{i, j}^{t+1}= \begin{cases}Q \cdot \exp \left(\frac{X_{\text {worst }}^t-X_{i, j}^t}{i^2}\right) & \text { if } i>n / 2 \\ X_p^{t+1}+\left|X_{i, j}^t-X_p^{t+1}\right| \cdot A^{+} \cdot L & \text { otherwise }\end{cases}$ (9)
$X_{i, j}^{t+1}= \begin{cases}X_{\text {best }}^t+\beta \cdot\left|X_{i, j}^t-X_{\text {best }}^t\right| & \text { if } f_i>f_g \\ X_{i, j}^t+K \cdot\left(\frac{\left|X_{i, j}^t-X_{\text {worst }}^t\right|}{\left(f_i-f_w\right)+\varepsilon}\right) & \text { if } f_{i=} f_g\end{cases}$ (10)
4.3 DELM hyperparameters optimization based SSA
In this paper, the sparrow optimization algorithm is applied to DELM to find the optimum of its parameters. The output layer weights and thresholds of DELM are updated by the least squares method, while the input layer weights and thresholds are randomly generated by the orthogonal matrix. Therefore, SSA is used here for parameter optimization of the input layer weights and thresholds.
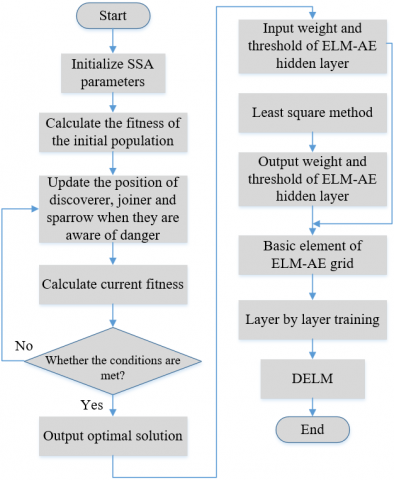
The optimization process is as Figure 6, and specific steps are as follows:
(1) Initialization. This process includes the population size N, the number of producers pNum, the number of warning sparrows SNum, the dimensionality of the objective function D, the upper and lower bounds on the initial values, the maximum number of iterations and the solution accuracy.
(2) Calculate the fitness value, select the current best fitness value and its corresponding position, and the worst fitness value and its corresponding position.
(3) Iterative and update. The fitness value of each sparrow is calculated again after one iteration and the location information of the discoverer, joiner and scout is updated.
(4) Evaluate. According to the current state of the sparrow population, update the optimal and worst positions and fitness values of the whole population, determine whether the maximum number of iterations or the solution condition is reached, and if yes, output the optimal value, if not, return (2).
(5) The results are applied to the DELM model. The whole optimization process is shown in Figure 6.
Figure 6. Flow chart of SSA optimized DELM
The DELM network is constructed using three hidden layers. Through repeatedly simulating trials, the number of nodes in the three hidden layers is determined to be 30, 20, and 10 respectively. The network activation function is the tanh function, and the Tikhonov regularization is set to 1012. The population number, iteration times, percentage of discoverers, and warning value of SSA are 30,60, 0.6, and 0.7, respectively.
In this article, the DELM algorithm was used to model NOx emission concentration The DELM-based prediction results are compared with the operating results and compared with ELM, deep belief network (DBN), and deep neural network (DNN) algorithms. The prediction performance is evaluated by root mean squared error (RMSE), coefficient of determination (R2), mean absolute error (MAE), and accuracy (Acc). All the definitions of these evaluation indicators are shown as Eqns (11)-(15).
$M A E=\frac{1}{n} \sum_{i=1}^n\left|\hat{y}-y_i\right|$ (11)
$R M S E=\sqrt{\frac{1}{n} \sum_{i=1}^n\left(\hat{y}_i-y_i\right)^2}$ (12)
$R^2=1-\frac{\left[\sum_{i=1}^n\left(\hat{y}_i-y_i\right)^2\right] / n}{\left[\sum_{i=1}^n\left(\bar{y}_i-y_i\right)^2\right] / n}$ (13)
$A c c=\frac{100}{n} \sum_{i=1}^n c_i$ (14)
$c_i=\left\{\begin{array}{l}1, \text { if }\left|\left(\hat{y}_i-y_i\right)\right| \leqslant e \\ 0, \text { otherwise }\end{array}\right.$ (15)
where n is samples number; $\bar{y}_i$ represents average value of NOx measured values, yi is NOx measured values; $\hat{y}_i$ indicates predicted values of NOx. e is the acceptable threshold error, the value of e is selected as 5 mg/m3, 20 mg/m3 and 50 mg/m3.
5.1 Effect of feature selection on prediction results
In the process of NOx prediction, the impact of feature selection on the prediction results mainly relies on the selection of input variables. The input variables must be selected from the processes related to NOx generation. This section analyzes the comparison of the results of NOx modeling without feature selection and XGBoost feature selection. Twenty-five variables affecting NOx emission concentration were selected according to the XGBoost, and effectiveness of the prediction model was verified on the 2000 operating data of the power plant. Table 1 summarizes the results of the comparison. The MAE of the prediction model after XGBoost feature selection is reduced by 4.05%, the R2 is improved by 2.94% and the RMSE is reduced by 6.16%. It can be seen from the Table 1 that better prediction results can be obtained by the XGBoost feature selection method, because feature selection can avoid too many redundant variables in the selection of input variables.
Table 1. The results of feature selection
|
Indicators |
SSA-DELM |
XGboost-SSA-DELM |
|
MAE |
2.96 |
2.84 |
|
R2 |
0.954 |
0.982 |
|
RMSE |
7.30 |
6.85 |
5.2 Comparation of different model algorithms
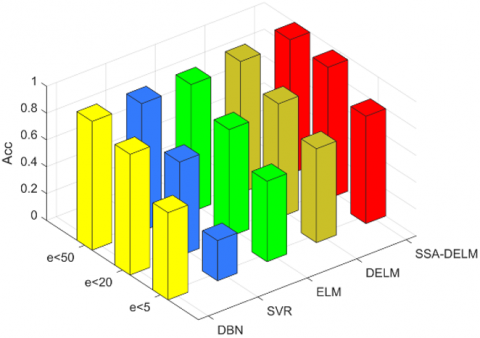
Figure 7. Accuracy comparison of different algorithm
To verify the effectiveness of the model, the DELM model was compared with three prediction algorithms: ELM, SVR, and DBN. Meanwhile, the comparison before and after the optimization of SSA algorithm applied to DELM algorithm was carried out. 25 relevant parameters were selected as the input variables by XGBooost feature selection, and the data set was the 2000 DCS operation data. Figure 7 presented the accuracy comparison of different algorithms. For the case of e smaller than 20 mg/m3, the accuracy obtained by SSA-DELM is approximately 100%. The greatest obtained accuracies for each case are, in descending order, the SSA-DELM, DELM, DBN, ELM and SVR.
Table 2 listed the performance comparison of the different models. It can be seen that two models all achieve good performance. The RMSEs obtained by SSA-DELM achieves 6.85 mg/m3, and MAE achieves 2.84 mg/m3, and R2 achieves 0.982, respectively. According to the results, the prediction effect is increased after optimization of DELM input layer weights and thresholds, which indicated that the accuracy of model can be improved through SSA hyperparameter optimization.
Table 2. Performance comparison of different algorithm
|
Indicators |
DBN |
SVR |
ELM |
DELM |
SSA-DELM |
|
MAE |
4.89 |
7.43 |
6.24 |
3.37 |
2.84 |
|
R2 |
0.945 |
0.866 |
0.936 |
0.963 |
0.982 |
|
RMSE |
8.17 |
10.16 |
9.34 |
7.36 |
6.85 |
5.3 Influence analysis of CFD simulation data
Table 3. The results of feature selection
|
Indicators |
DCD |
DCD+CFD |
|
MAE |
2.84 |
2.58 |
|
R2 |
0.982 |
0.990 |
|
RMSE |
6.85 |
6.44 |
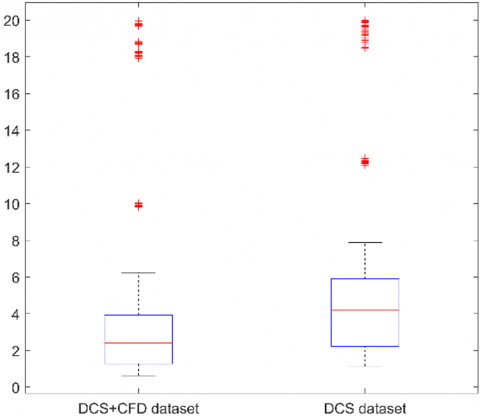
Figure 8. The error boxplot of different data set
In order to evaluate the data fusion model, the 25 variables mentioned above were still used as the input variables of the model and SSA-DELM algorithm was used to model. Two data sets were used for comparative analysis, one with 1840 DCS data and 160 CFD data for fusion, and one with all 2000 DCS data. In the modeling process, 1500 samples were used for training and 500 samples were used for testing. As was shown in Table 3, the prediction performance of the data fusion model for NOx generation with R2 is improved by about 1%. It was proved that the CFD data improved the generalization and expression ability of the model. Because of the addition of CFD data based on combustion mechanisms, more possible combustion conditions were generated and enriches the knowledge of the data set.
The absolute error boxplot of the two data sets is shown in Figure 8. We can intuitively see that the absolute errors of DCS-CFD data set is less than DCS data set. The boxplots of absolute error of the DCS-CFD data model is the narrowest, the smaller distance between the upper and lower edges, and the smaller between the upper and lower quartiles. We can conclude that the DCS-CFD data set model has better fitting effect and prediction ability.
This work has presented a NOx emission prediction model for 350MW coal-fired units based on XGBoost-SSA-DELM and validated by fusing DCS operation data with CFD simulation results. The results show that the model can predict NOx concentration with high accuracy. The R2 of the test data set is more than 0.98%, and the MAE and RMSE are lower than 3 and 7 mg/m3, respectively. The following conclusions are obtained:
(1) XGBoost feature selection is used to reduce the dimensionality of input variables and to improve the prediction accuracy ;
(2) The data-driven model is sensitive to data, the fusion of DCS data and CFD data as the training set enriches the diversity of working condition.
(3) SSA is applied to the parameter optimization of DELM, which reduces the randomness of selection of the input layer weights and thresholds, and achieves better NOx prediction results. It can be used as the basis for the optimal adjustment of combustion process and accurate control of denitrification system.
[1] Qiao, J. (2022). A novel online modeling for NOx generation prediction in coal-fired boiler. Science of the Total Environment, 847: 157542. https://doi.org/10.1016/j.scitotenv.2022.157542
[2] Choi, C.R., Kim, C.N. (2009). Numerical investigation on the flow, combustion and NOX emission characteristics in a 500 MWe tangentially fired pulverized-coal boiler. Fuel, 88(9): 1720-1731. https://doi.org/10.1016/j.fuel.2009.04.001
[3] Ti, S., Chen, Z., Li, Z., Xie, Y., Shao, Y., Zong, Q., Zhang, Q.H., Zhang, H., Zeng, L.G., Zhu, Q. (2014). Influence of different swirl vane angles of over fire air on flow and combustion characteristics and NOx emissions in a 600 MWe utility boiler. Energy, 74, 775-787. https://doi.org/10.1016/j.energy.2014.07.049
[4] Fan, W., Chen, J., Feng, Z., Wu, X., Liu, S. (2020). Effects of reburning fuel characteristics on NOX emission during pulverized coal combustion and comparison with air-staged combustion. Fuel, 265: 117007. https://doi.org/10.1016/j.fuel.2020.117007
[5] Wang, Y., Zhou, Y. (2020). Numerical optimization of the influence of multiple deep air-staged combustion on the NOx emission in an opposed firing utility boiler using lean coal. Fuel, 269: 116996. https://doi.org/10.1016/j.fuel.2019.116996
[6] Tan, P., Tian, D., Fang, Q., Ma, L., Zhang, C., Chen, G., Zhong, L., Zhang, H. (2017). Effects of burner tilt angle on the combustion and NOx, emission characteristics of a 700 MWe deep-air-staged tangentially pulverized-coal-fired boiler. Fuel, 196: 314-324. https://doi.org/10.1016/j.fuel.2017.02.009
[7] Jin, W., Si, F., Cao, Y., Ma, H., Wang, Y. (2022). Numerical optimization of separated overfire air distribution for air staged combustion in a 1000 MW coal-fired boiler considering the corrosion hazard to water walls. Fuel, 309: 122022. https://doi.org/10.1016/j.fuel.2021.122022
[8] Choi, M., Park, Y., Li, X., Kim, K., Sung, Y., Hwang, T., Choi, G. (2020). Numerical evaluation of pulverized coal swirling flames and NOx emissions in a coal-fired boiler: Effects of co- and counter-swirling flames and coal injection modes. Energy, 217: 119439. https://doi.org/10.1016/j.energy.2020.119439
[9] Chang, J., Wang, X., Zhou, Z.,Chen, H., Niu, Y. (2021). CFD modeling of hydrodynamics, combustion and NOx emission in a tangentially fired pulverized-coal boiler at low load operating conditions. Advanced Powder Technology, 32(2): 290-303. https://doi.org/10.1016/j.apt.2020.12.008
[10] Wang, G., Awad, O. Liu, S., Shuai, S., Zhang, Z. (2020). NOx emissions prediction based on mutual information and back propagation neural network using correlation quantitative analysis. Energy, 198: 117286. https://doi.org/10.1016/j.energy.2020.117286
[11] Zhai, Y., Ding, X., Jin, X., Zhao, L. (2020).Adaptive LSSVM based iterative prediction method for NOx concentration prediction in coal-fired power plant considering system delay.Applied Soft Computing, 89: 106070. https://doi.org/10.1016/j.asoc.2020.106070
[12] Tang, Z., Wang, S., Chai, X., Cao, S., Ouyang, T., Li, Y. (2022). Auto-encoder-extreme learning machine model for boiler NOx emission concentration prediction. Energy, 256: 124552. https://doi.org/10.1016/j.energy.2022.124552
[13] Yang, T., Ma, K., Lv, Y., Bai, Y. (2020). Real-time dynamic prediction model of NOx emission of coal-fired boilers under variable load conditions. Fuel, 274: 117811. https://doi.org/10.1016/j.fuel.2020.117811
[14] Wang, F., Ma, S., Wang, H., Li, Y., Zhang, J. (2018). Prediction of NOx emission for coal-fired boilers based on deep belief network. Control Engineering Practice, 80: 26-35. https://doi.org/10.1016/j.conengprac.2018.08.003
[15] Wang, Y., Yang, G., Xie, R., Liu, H., Li, X. (2021). An Ensemble Deep Belief Network Model Based on Random Subspace for NOx Concentration Prediction. ACS Omega, 6(11): 7655-7668. https://doi.org/10.1021/acsomega.0c06317
[16] Blackburn, L., Tuttle, J., Andersson, K., Fry, A., Powell, K. (2022). Development of novel dynamic machine learning-based optimization of a coal-fired power plant. Computers and Chemical Engineering, 163: 107848. https://doi.org/10.1016/j.compchemeng.2022.107848
[17] Chennippan, M., Bhaskaran, P.E., Subramaniam, T., Meenakshipriya, B., Krishnamurthy, K., Kumar, K.A. (2020). Design and experimental investigations on NOx emission control using FOCDM (fractional-order-based coefficient diagram method)-PIλDµ controller. Journal Européen des Systèmes Automatisés, 53(5): 695-703. https://doi.org/10.18280/jesa.530512
[18] Haddad, L., Aouachria, Z., Haddad, D. (2020). How to use hydrogen in a new strategy to mitigate urban air pollution and preserve human health. International Journal of Sustainable Development and Planning, 15(7): 1007-1015. https://doi.org/10.18280/ijsdp.150705
[19] Yu, H., Gao, M., Zhang, H., Chen, Y. (2021). Dynamic modeling for SO2-NOx emission concentration of circulating fluidized bed units based on quantum genetic algorithm - Extreme learning machine. Journal of Cleaner Production, 324: 129170. https://doi.org/10.1016/j.jclepro.2021.129170
[20] Ye, T., Dong, M., Long, J., Yang, Z., Liang, Y., Lu, J. (2022). Multi-objective modeling of boiler combustion based on feature fusion and Bayesian optimization. Computers and Chemical Engineering, 165: 107913. https://doi.org/10.1016/j.compchemeng.2022.107913
[21] Shi, Y., Zhong, W., Chen, X., Yu, A.B., Li, J. (2019). Combustion optimization of ultra supercritical boiler based on artificial intelligence. Energy, 170: 804-817. https://doi.org/10.1016/j.energy.2018.12.172
[22] Lv, M., Zhao, J., Cao, S., Shen, T. (2022). Prediction of the 3D Distribution of NOx in a Furnace via CFD Data Based on ELM. Frontiers in Energy Research, 10: 848209. https://doi.org/10.3389/fenrg.2022.848209
[23] Pathy, A., Meher, S., Balasubramanian, P. (2020). Predicting algal biochar yield using eXtreme Gradient Boosting (XGB) algorithm of machine learning methods. Algal Research, 50: 102006. https://doi.org/10.1016/j.algal.2020.102006
[24] Xue, J., Shen, B. (2020). A novel swarm intelligence optimization approach: sparrow search algorithm. Systems Science & Control Engineering, 8(1): 22-34. https://doi.org/10.1080/21642583.2019.1708830