OPEN ACCESS
Thermodynamics is brief, simple, unambiguous and improving. Yet, confusion reigns in the field. The word “entropy” is pasted on almost any new thing, without any respect for its proper definition in thermodynamics. Every author bows to his own maximum or minimum principle, even when it contradicts English, not just thermodynamics. Minimizing resistance cannot be the same as maximizing resistance. Minimizing entropy generation cannot be the same as maximizing entropy generation. Because of the word “entropy”, many believe that entropy generation minimization and maximization are covered by the second law, which is incorrect, twice. Because for an isolated system (or an adiabatic closed system) the second law states that the system entropy inventory increases during changes inside the system, many believe that the second law accounts for organization, evolution, and the arrow of time. This too is incorrect. It is time for a reality check, and this means to take a look at nature, at the physics, at the science of all the natural things that “happen”. Here then is a review of the few, the noble, the laws with which in science we cover the few distinct phenomena that nature is made of.
Constructal law, Design, Organization, Life, Evolution, Arrow of time, Thermodynamics, Entropy.
Words have meaning. This is why words matter. This is also why it is necessary to define the terms in this discussion, because otherwise we wander aimlessly, lost on the Tower of Babel of entropy.
The human observation that certain things happen innumerable times the same way is one natural tendency, i.e., one phenomenon. To observe the phenomenon is empiricism. The law of physics is the compact statement (text, or formula) that summarizes the innumerable observations of the same kind. To rely on the law to experience a purely mental viewing of how things should be (i.e., to predict future observations) is theory.
The phenomenon covered by the first law of thermodynamics is the “what goes up must come down”. Today, we recognize this more generally as the conservation of energy, from kinetic to potential when a body is thrown upward, to the energy flow (from heat into work) through a thermodynamic system such as a power plant.
The phenomenon covered by the second law is the “one way”, such as the flow of water under the bridge. Today, we recognize this natural tendency as irreversibility. Every flow, by itself, proceeds from high to low. Fluid through a duct flows from high pressure to low pressure. Heat through an insulation leaks from high temperature to low temperature. If you do not know beforehand which is the high and which is the low, then the direction of the flow will tell you. Why, because it is the law, and all thermodynamic systems obey the law.
The phenomenon covered by the constructal law [1-3] is natural organization, evolution and life [4]: the occurrence and evolution of freely morphing configurations in every thing that flows and moves more easily over time. Observations of this kind are everywhere: river basin evolution, lung architecture evolution, city traffic evolution, aircraft evolution. These observations reveal the arrow of time [5] in nature, which points from existing flow configurations to new configurations through which the flowing is easier. Not the other way around. Why, because it is the law, and all systems obey the law.
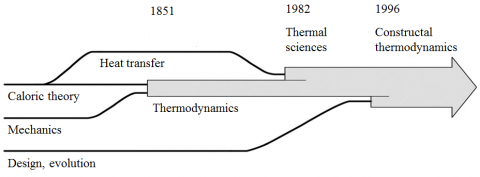
Figure 1. The evolution and spreading of thermodynamics during the past two centuries (after Ref. 6, Diagram 1, p. viii)
Thermodynamics before 1996 was the thin book comprising the first law and the second law (Fig. 2) [7]. It is an all-encompassing science story written in very few words. The two laws apply to “any system” imaginable. Their few words are system, boundary, environment, state, properties, equilibrium, and nonequilibrium. The “any system” is the most general system with flows in it, the nonequilibrium system, and the flow system. This most general system can have nonuniformities internally (pressure, temperature, concentration) that drive currents through its various subsystems. It can have any configuration (organization, design), which is not specified.
Science began with principle-based rationalizations of the images (designs) that humans perceive all around. It began with geometry and mechanics, which are about configurations, their principles, and the contrivances made based on configurations and principles. Science has always been about the human urge to make sense out of what we discern: numerous observations that we tend to store compactly as phenomena and, later, even more compactly as laws that account for the phenomena.
The first law and the second law have equal standing. Each is a “first principle”. The permanence and extreme generality of the two laws are consequences of the fact that in thermodynamics the “any system” is a black box. It is a region of space, or a collection of matter without specified shape and structure. The two laws are global statements about the balance or imbalance of the flows (mass, heat, work, entropy) that flow into and out of the black box. They say absolutely nothing about design, organization and evolution.
Figure 2. What is law, and what is not
The laws of thermodynamics for a closed system executing cycles, or operating in steady state, in communication with two temperature reservoirs [7]. Thermodynamics is about systems viewed as black boxes, without configuration.
Nature is not made of boxes without configuration such as Fig. 2. The systems that we identify in nature have shape, structure and evolution. They are resoundingly macroscopic, finite size, and recognizable as lines drawn on a background. They have organization, construction, configuration, pattern, rhythm and sound. The very fact that they have names (river basins, blood vessels, trees) indicates that they have unmistakable appearances and meaning.
In 1996 [8] and in the book the following year [1], I pointed out that the laws of thermodynamics do not account completely for the systems of nature, even though scientists have built thermodynamics into thick books in which the two laws are just the introduction. The body of the doctrine is devoted to contriving, describing, and improving designs that seem to correspond to systems found in nature, and can be used by humans to make life easier.
If physics was to account for the systems of nature completely, then thermodynamics had to be strengthened with an additional self-standing law—with another first principle—that covers all phenomena of design occurrence and evolution. To achieve this, the constructal law states briefly that “For a finite-size flow system to persist in time (to live), it must evolve in such a way that it provides easier access to the imposed (global) currents that flow through it” [8]. The new research direction defined by the constructal law is documented in a growing literature, review articles [9-14] and books [15-27].
The constructal law is the definition of life [4] in the broadest possible sense: to be alive, a system must flow and be free to morph in time so that its currents flow more and more easily. “Live” are the water streams in the river basins and the streams of animal mass flowing on the landscape, which are better known as animal locomotion and migration. Live are the animate and the inanimate systems that flow, move, and change configuration to flow better. The constructal law commands that the changes in configuration must occur in a particular direction in time [5] (toward designs that allow currents to flow more easily). The constructal law places the concepts of design and evolution and life centrally in physics.
The constructal law is not a statement of maximization, minimization, or any other mental image of “end design” or “destiny”. There is no such thing, in spite of loud claims that it exists (fascism, communism, religious fundamentalism). The constructal law is about the direction of evolution in time, and the fact that design in nature is not static: it is dynamic, ever changing, like the images on the screen at the cinema. This is what design and evolution are in nature, and the constructal law captures them. Evolution never ends.
“Believe those who are seeking the truth. Doubt those who find it.” André Gide.
There have been many proposals of end-design in science, but each addresses a narrow domain. The body of statements that have emerged is self-contradictory, and the claim that each is a general principle is easy to refute. Here are the best known statements (their sources are listed in Refs. [12, 14]):
(i) Minimum entropy generation and maximum efficiency are used commonly in engineering and biology.
(ii) Maximum entropy generation is being invoked in geophysics.
(iii) Maximum “fitness” and “adaptability” (robustness, resilience) are used in biology.
(iv) Minimum flow resistance (fluid flow, heat transfer, mass transfer) is invoked in engineering, river mechanics and physiology.
(v) Maximum flow resistance is used regularly in physiology and engineering, e.g. maximum resistance to loss of body heat through animal hair and fur, or through the insulation of power and refrigeration plants, the minimization of fluid leaks through the walls of ducts, etc.
(vi) Minimum travel time is used in urban design, traffic, transportation.
(vii) Minimum effort and cost is a core idea in social dynamics and animal design.
(viii) Maximum profit and utility is used in economics.
(ix) Maximum territory is used for rationalizing the spreading of living species, deltas in the desert, and empires.
(x) Uniform distribution of maximum stresses is used as an “axiom” in rationalizing the design of botanical trees and animal bones.
(xi) Maximum growth rate of flow disturbances (deformations) is invoked in the study of fluid flow disturbances and turbulence.
(xii) Maximum power was proposed in biology.
Even though these statements are contradictory, local, and disunited, they demonstrate that the interest in placing design phenomena deterministically in science is old, broad and thriving. Reviews of the progress being made with the constructal law [9-14] show that the diverse phenomena addressed ad hoc with statements (i) – (xii) are manifestations of the single natural tendency that is captured by the constructal law. This is why the constructal law covers the territory populated by disconnected optimality principles. One example is the flow of stresses phenomenon [19] that accounts for the emergence of solid shape and structure in vegetation, skeleton design, and technology. Previously, this was an ad hoc optimality statement [see statement (x) above] foreign to other statements about moving, flow systems. With the constructal law, now we see that the flow of stresses is an integral part of the design-generation phenomenon of moving mass more and more easily on the landscape.
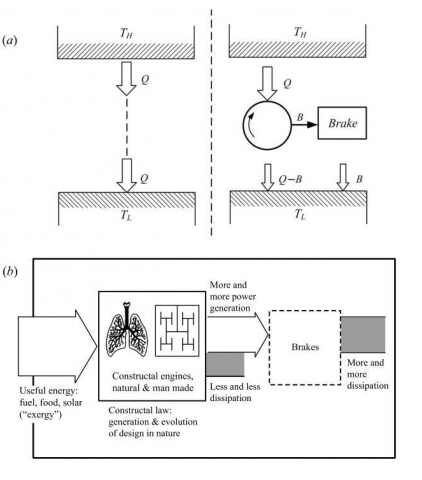
Figure 3. The whole earth is an engine + brake system, containing innumerable smaller “engine + brake” systems (winds, ocean currents, animals, and human and machine species)
The strident contradiction between minimum and maximum entropy generation [see (i) and (ii) above], was resolved based on the constructal law [15, 28]. As shown in the captions of Figs. 3 and 4, the flowing nature is composed of systems that move and flow in a way that is thermodynamically equivalent to engines that produce power and dissipate their power completely in order to move things on the landscape. The icon of the moving design of nature is the “engine + brake” system.
In time, the “engines” of nature evolve into configurations that flow more easily, and this means that their designs evolve toward less entropy generation, and more production of motive power per unit of useful energy (exergy) used. At the same time, the “brakes” of nature destroy the produced power, and this means that the
Figure 4. The engine + brake design of nature
The constructal law governs how the system emerges and persists: by generating a flow architecture that distributes imperfections through the flow space and endows it with configuration. The ‘engine’ part evolves in time towards generating more power (or less dissipation), and as a consequence, the ‘brake’ part evolves toward more dissipation. (a) The original version of the ‘engine and brake’ image of every thing that moves on Earth (A. Bejan, Entropy Generation through Heat and Fluid Flow, Wiley, New York, 1982). Q is the heat input to the engine, and B is the work output dissipated completely in the brake. (b) The engine and brake design of nature is represented by the flow of useful energy into the earth (the large rectangle), the partial destruction of this flow in the animate and inanimate engines (the larger square), followed by the complete destruction of the remaining useful energy stream in the interactions with the environment (the brakes shown in the smaller square) [15, 28]. In time, all the flow systems exhibit the constructal-law tendency of generating ‘designs’, and this time arrow means less dissipation in the engines and more dissipation in the brakes.
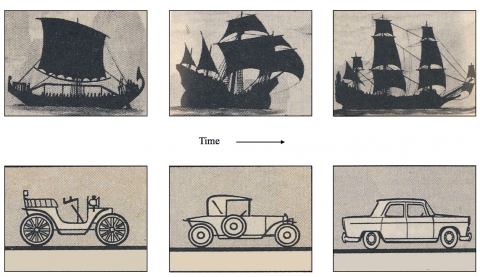
Figure 5. The fallacy of the claim that evolution in nature is governed by the “maximization of entropy generation”
In time, the organization of a steady flow system is replaced by a new organization that generates more power (and more movement) for the same rate of fuel input as in the older design. The evolution of the system flow organization is toward a smaller entropy generation rate, not a greater one, and the evolutionary design never ends (The drawings are from Petit Dictionnaire Français, Librairie Larousse, Paris, 1956, pp. 48 and 62).
Brake designs evolve toward configurations that dissipate more power. Examples are the transition from laminar flow to turbulent flow [1, 6], and the transition to round cross sectional shape in flat (two-dimensional) jets and plumes, turbulent or laminar [29].
The law of physics is not the “maximum” or the “minimum”, or the fact that the “engine + brake” constitution of nature brings them together. The law of physics is the evolution of configurations (engines, brakes) in the constructal-law direction in time. The symbiotic evolution of “brake” configurations is oriented in the same direction in time as the evolution of “engine” configurations.
Maximization of entropy generation rate is blatantly wrong when invoked in the evolution of live (flow) systems, from river basins to animals and vehicles (human & machine species). Consider the evolution of the two steady-flow systems sketched in Fig. 5: each system is defined by a rectangular boundary, sail boat or automobile. The architecture of the sailing boat evolved just like the wave on the ocean and the orientation of the tabular iceberg: perpendicular to the wind direction, to engage the wind better. Or, imagine that the system is a road vehicle, driven by the steady consumption of fuel. It is like any other animal, an open system that in the time frame of our life can be modelled as flowing in steady state (fuel and air flow in, exhaust flows out). Right away, we see that maximization of anything (e.g., entropy generation rate) is not part of the physics, because the system operates in steady state, its entropy inventory is constant, and so is its rate of entropy generation.
Evolution does happen, but on a longer time scale. Inside the system, the vehicle organization is replaced by a newer design, the motor of which produces more power for the same rate of exergy input, or fuel consumption. This means that on the broader time scale of this design change, the entropy generation rate of the system has decreased, not increased. This contradicts even louder the claim that maximization of entropy generation is the principle that captures the physics of evolution in nature. Had the system been evolving toward greater entropy generation rate, the truck and the animal would eventually stop and die, because in this direction the power that drives them would vanish.
There are many authors who even today consider maximization (or minimization) as obvious, and claim that organization in nature is demanded by the second law of thermodynamics. Why are educated minds tempted to venture on this path?
Because words matter, all right, but when the words are old their meaning is lost even to the educated speakers. Maxima and minima were introduced in the thermodynamics doctrine by pioneers such as Clausius, Gibbs and Helmholtz. From this, an entire language of extrema emerged, as in the modern textbook of Callen [30]. In every case, the extremum emerged by invoking the first law and the second law in the analysis of a closed system that executes a process the end of which is equilibrium, and equilibrium means that nothing flows inside the system. In thermodynamics, the better known word for this state is death, or the dead state.
The first “maximum” in a closed system at equilibrium was made famous by Clausius, who wrote about a very special case of closed system: the isolated system. Nothing crosses the boundary of an isolated system, no mass flow, no heat transfer, no work transfer. By invoking the first law and the second law, Clausius declared that in the universe (that was his example of an isolated system) the entropy tends to a maximum, while the energy remains constant.
This idea came and stayed as the entropy maximum principle. It is nothing more than a restatement of two principles combined: the first law and the second law. I called such restatements the combined law [1]. Soon after Clausius, additional combined-law statements came and stayed as minimum energy principles:
· The energy minimum principle: a closed system approaching equilibrium at constant entropy and volume tends to a state of minimum energy.
· The enthalpy minimum principle: a closed system approaching equilibrium at constant entropy and pressure tends to a state of minimum enthalpy.
· The Helmholtz free energy minimum principle: a closed system approaching equilibrium at constant temperature and volume tends to a state of minimum Helmholtz free energy.
· The Gibbs free energy minimum principle: a closed system approaching equilibrium at constant temperature and pressure tends to a state of minimum Gibbs free energy.
The keyword in these minimum principles is equilibrium, which refers to states with no movement, no flow, no currents, no organization, no evolution—in short, no life—inside the system.
Conclusion: the second law, like the first law, is not the law that accounts for the natural phenomenon of organization, design and evolution in “live” systems. There is an arrow of time in the second law for very special systems (isolated, or adiabatic & closed), but it points toward death, no movement, and no life.
Many confuse “pattern” with organization (or design) in nature. The highly ordered atoms in a metal crystal at equilibrium with the ambient have pattern, but they constitute a dead system. The snowflake, on the other hand, is alive with heat currents (from ice to ambient), which is why the snowflake morphs as it grows. This is why the snowflake “movie” is predictable from the constructal law [1, 31]. To confuse pattern with organization (flowing design) is to confuse death with life.
Maximum entropy in an isolated system at equilibrium has nothing to do with maximum (or minimum) entropy generation in a flow system, for example, in steady-state entropy generation (e.g., Fig. 2). The second law stated by Clausius (and Kelvin and Planck) says absolutely nothing about shape and structure in the black-box system, and even less about particles, statistics, disorder and other such concepts that suggest “configuration” but do not predict or exhibit any. Yet, we often hear that the end-design idea of maximization of entropy generation (ii) is a law of maximum entropy production, which follows deductively from the second law of thermodynamics. This is not true.
Here is the correct statement of the second law, made by two of its original proponents in 1851-1852:
Clausius: No process is possible whose sole result is the transfer of heat from a body of lower temperature to a body of higher temperature.
Kelvin: Spontaneously, heat cannot flow from cold regions to hot regions without external work being performed on the system.
We often read that the second law states that “entropy must increase”, and that the “classical” laws of thermodynamics pertain to ''equilibrium states”. Many even teach that thermodynamics should be called thermo “statics”. Such statements are not thermodynamics.
For example, a physicist [32] wrote in 2015 that “the second law … applies to closed macroscopic systems consisting of an extremely large number of particles, such as liquids or gases …” This is simply not true. Read the second law statements above. They hold for “any system”.
The second law says absolutely nothing about “equilibrium states”, “entropy”, “particles”, “classical”, and “statics”. Important to remind everyone is that “thermodynamics” is the science that brings together two kinds of movement, heating and working, previously seen as separate (caloric versus mechanics, Fig. 1). The only relevant question about the second law statement is whether it is correct. The evidence is massively in support of answering “yes”, based on the machines built successfully by relying on the second law of thermodynamics of Clausius and Kelvin. These machines are every day futuristic (not “classical”), they are full of life and motion (not in “equilibrium”), and are dynamic (not “static”).
The second law says nothing about “disorder”. Many confuse the second law with the view that in a box filled with particles the assembly tends toward a larger number of possible energy states [33, 34]. This is the core idea of statistical thermodynamics, yet lost in the teaching of it are two important observations:
First, to assume a swarm of particles in a closed box is to throw away the “any system” power of thermodynamics. The any-system (Fig. 2) is the general, and the box with bouncing particles is the extremely special, with a postulated configuration.
Second, no one has seen particles, their disorder, and their tendency toward greater disorder. From such blindness, how can there be a “law of increasing disorder”? This is nonsense, because all around us we are struck by design, self-organization, change (design evolution) and order out of lack of order.
Third, decades before statistical thermodynamics, the second law and the first law were stated with reference to systems of unspecified size (e.g., heat engines, Fig. 2), not infinitesimal.
The phenomenon covered by the constructal law in physics is organization and evolution in nature. The constructal law accounts for the natural tendency of evolution toward flow configurations that provide easier access to what flows. The word “access” means the opportunity to enter and move through a confined space such as a crowded room. This mental viewing covers all the flow design and evolution phenomena, animate and inanimate, because they all morph to enter and to flow better, more easily, while the flow space is constrained. This is why “finite-size” is present in the statement of the constructal law.
If the reader has a particular flow system in mind, say, air flow in lungs or electricity in lightning, then the reader can express the evolutionary design toward easier access in terms of locally meaningful terms and units. Yet, the fluid flow terminology of the lungs has no place in the analysis of the flow of electricity as a lightning tree, and vice versa. What is the same in both examples is a first principle: the evolution of design toward easier access, through changes in flow configuration in a finite-size space.
The constructal law is universally valid precisely because it is not a statement of optimality, destiny and end design [many optimization statements have failed: see again the ad hoc statements (i) – (xii)]. A new law does not have to be stated in mathematical terms (e.g., thermodynamic variables, units). First is the idea, not the mathematical formula. The second law of thermodynamics was stated in words, as a mental viewing, not mathematically (review the Clausius and Kelvin statements). The mathematization of the second law statement (and of thermodynamics) came later. Likewise, the 1996 statement of the constructal law was followed in 2004 by a complete mathematical formulation of constructal-law thermodynamics [35].
In the two decades since 1996, we have seen an accelerated activity of using the constructal law to predict design and evolution in nature, and put the constructal law to good use in engineering and society. These contributions are reviewed in detail in Refs. [9-27]. In biology, the constructal law was used to explain the design of corals, bacterial colonies and plant roots, the architecture of lungs, the heat transfer in the circulatory system, and many features of dendritic flow architecture in vascular design. In geophysics, the constructal law was offered as theoretical basis for plate tectonics, beach sand and slope, the scaling laws of river basins, and the evolution of constructal morphology in all of nature. In engineering, the constructal law has triggered a technological revolution toward vascular design in many domains such as the cooling of electronics, the cooling of turbine blades, high density heat exchangers, self-healing composite materials, the design of nanofluids, chemical engineering equipment, solid-fluid structures, fuel cells, and hydraulics engineering. In social dynamics, the constructal law has inspired an activity that offers a physics foundation for phenomena of pattern and emergence in social dynamics: written language, global air traffic, sustainability, warfare strategy, and the rankings (hierarchy) of universities in the global flow of education and knowledge [36-38].
What works is kept. Flow architectures that offer greater flow access for the whole persist and are joined by even better ones. Together the vascular tapestries of the old and the new carry the global flow (geo, bio, socio) easier, farther and longer lasting than the old alone. This is why the persistent designs seem to become more complex, modular, with many elemental flow systems inside flow constructs, and many constructs inside larger constructs. The flow of water, migratory animals, and human trade is this hierarchy of “few large and many small”, many river basins inside larger river basins, and many deltas inside larger deltas. This is the natural, physics origin of hierarchy, and hierarchy is good for the flow performance of the whole. With hierarchy come many other features that are good for flow performance: robustness, ability to change, sustainability, survivability, in one word: life.
People like to say that we cannot witness evolution because the time scale of evolution is immensely longer than human lifetime. This view has its roots in biology education, where it may have been correct. The fact is that “evolution” is not about biology. It is a much broader concept of physics. Evolution means change in configuration, which occurs in a discernible (purposeful) direction in time.
Liberated as we think about evolution, we can witness evolution in our lifetime. How, by looking at river basin evolution, turbulent plume evolution (Fig. 6), sports evolution, writing evolution, and all the other evolutionary designs that facilitate flow everywhere.
Figure 6. Evolution: above a certain height all turbulent plumes acquire round cross sections [29]
Left: flat plume rising from a row of smoke stacks; Middle: round plume rising from a concentrated fire; Right: plume above a brush fire
Technology evolution is the most familiar movie to watch and to predict its plot. One movie to watch is the evolution of commercial aviation [39]. Another is the evolution toward miniaturization in flow systems and components used across all technologies [40, 41]. In the evolutionary design of cooling technologies for electronics packages, it turns out that (in time, and at smaller dimensions) the cooling by natural convection must be replaced by forced convection and, in the future, by conduction (thermal diffusion). The prediction is that stepwise transitions must occur between configurations (and their performance levels) in this time sequence: natural convection, forced convection, conduction. Stepwise transitions in configuration and performance are also predictable for the evolution of vascular designs of all scales and across the entire range of sciences [42].
The constructal law is a contribution to physics and evolutionary biology because it simplifies and clarifies the terminology that is in use, and because it unifies it with the biology-inspired terminology that is in use in many other fields such as geophysics, economics, technology, education and science, books and libraries [12, 14]. This unifying power is both useful and potentially controversial because it runs against current dogma.
For example, the constructal designs of the river basin, the distribution of trees in the forest, the animal distribution and “animal flow” on the landscape, and all the other “few large and many small” designs such as the food chain, demography and transportation are viewed as whole architectures in which what matters is the better and better flow over the global system. In all such architectures, the few large and many small flow together. They collaborate, adjust, and collaborate again toward a better flowing whole, which is better for each subsystem of the whole. They do not compete. They do not kill each other. They flow together with organization and time arrow.
This holistic view of design phenomena represents a new step for scientific method. The concept of “better” is defined in physics terms, along with direction, which is organization, free morphing and evolution. In biology, this step unveils the concept of random events and mutations (“changes”, from this to that, from here to there) as a mechanism akin to river bed erosion [43], periodic food scarcity, plagues, scientific discovery, etc., which make possible running sequences of changes that are recognized widely as evolution. This holistic step places in physics the notions of natural selection, freedom to change and adapt, survival, and the idea that there are better designs, and that the future will be different from the past.
In summary, the constructal law is not an optimality statement about freeze-frame design. This aspect of the constructal law is especially important because it inspires the mind to fast-forward the design evolution process. This is in fact what the human mind does with any law of physics—the mind uses the law to predict the future: future natural behavior, and features of future phenomena.
The power to predict the future is well known to us. Because we know the principle of gravitational acceleration, we know how fast an object will fall at a certain time in the future. We do not have to wait to see the object falling. Knowing ahead is also an expression of the constructal law, because all animal design is about moving more and more easily on the landscape, and this includes the phenomenon of cognition – the urge to get smarter, understand and remember faster, so that the animal can get going and place itself out of danger.
Relying on the constructal-law direction to fast-forward the design is useful, but it can lead to confusion. For example, one can use the constructal-law direction as a justification for pursuing designs “in the limit”, for example, entropy generation minimization in engineering, or maximization of efficiencies in biology, and maximization of entropy generation in geophysics. This is correct, but the imagined end design (min, max) is neither reachable, nor is it to be confused with the phenomenon and the law, which is the natural tendency to evolve freely. The time direction of evolution is the natural phenomenon accounted for by the constructal law.
Many believe that the arrow of time in nature is imprinted on one-way (irreversible) phenomena, and is accounted for by the second law of Thermodynamics (see section 4). That arrow of time points toward “nothing moves”, and nothing moves is not nature, it means death. The arrow of time is painted much more visibly on live phenomena: the occurrence and change (evolution in time) of flow organization throughout nature, animate and inanimate [5]. In human flow systems, “knowledge” is the human ability to effect designchanges that facilitate life: human flows on the landscape. Knowledge spreads naturally because it facilitates flow access.
Everything that flows and moves does so because it is being pushed (Fig. 3). The push comes from the power generated because of flow design, because of contrivance. The power is destroyed in the process of moving mass horizontally on the world map, on land, on water and in the air. The dissipation resides in the environment that is displaced (penetrated) by the moving mass.
New configurations and rhythms emerge so that they offer greater access to what flows—greater access to the available space, areas and volumes, and persistence in time. As a special class of evolving designs, humanity today is kept moving (with “sustainability”) by the power produced in human machines. The designs morph along with us, and our movement is facilitated over time.
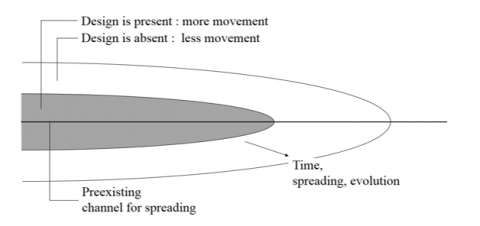
The spreading of design change on the human landscape is known as better science, knowledge, security, automobile technology, healthcare and many more. Knowledge means flow design change that is useful, and the ability to make it happen. Knowledge spreads on a territory naturally (Fig. 7). The boundary between those who know more and those who know less is advancing in time. The high is penetrating the low. In the high are the knowledgeable who move more than those in the low.
The physical effect of evolving design is more movement and greater access for all movers. This is the complete design of all animate or inanimate flow systems, from water flowing in river basins, to animal locomotion and urban traffic, and atmospheric and oceanic circulation. This is life and evolution, as physics.
Figure 7. Knowledge is the “contagious” spreading of the ability to effect design changes that facilitate greater and more lasting movement over the covered territory [5]
Prof. Bejan’s research is supported by the U. S. National Science Foundation.
1. A. Bejan, Advanced Engineering Thermodynamics, 2nd ed., Wiley, New York, 1997.
2. A. Bejan, The Physics of Life: The Evolution of Everything, St. Martin’s Press, New York, 2016.
3. A. Bejan and J.P. Zane, Design in Nature: How the Constructal Law Governs Evolution in Biology, Physics, Technology, and Social Organization, Doubleday, New York, 2012.
4. T. Basak, The law of life: “The bridge between physics and biology,” Phys Life Rev, Vol. 8, 2011, 249–252.
5. A. Bejan, “Maxwell’s demons everywhere: evolving design as the arrow of time,” Scientific Reports, 4, No. 4017, 10 February 2014. DOI: 10.1038/srep04017.
6. A. Bejan, Entropy Generation through Heat and Fluid Flow, Wiley, New York, 1982. DOI: 10.1115/1.3167072.
7. A. Bejan, “The constructal law of ‘designedness’ in Nature,” Meeting the Entropy Challenge, G.P. Beretta, A.F. Ghoniem and G.N. Hatsopoulos, eds., AIP Conference Proceedings, 1033, 2008. DOI: 10.1063/1.2979031.
8. A. Bejan, “Constructal-theory network of conducting paths for cooling a heat generating volume,” Int J Heat Mass Transfer, 40, 1997, 799–816; published 1 Nov. 1996. DOI: 10.1016/0017-9310(96)00175-5.
9. A. Bejan and S. Lorente, “Constructal theory of generation of configuration in nature and engineering,” J Appl Phys, 100, 2006, 041301. DOI: 10.1063/1.2221896.
10. H. Reis, “Constructal theory: From engineering to physics, and how flow systems develop shape and structure,” Appl Mech Rev, 59, 2006, 269–282. DOI: 10.1115/1.2204075.
11. A. Bejan and S. Lorente, “The constructal law of design and evolution in nature,” Philos Trans R Soc London, Ser B 365, 2010, 1335–1347. DOI: 10.1098/rstb.2009.0302.
12. A. Bejan and S. Lorente, “The constructal law and the evolution of design in nature,” Phys Life Rev, 8, 2011, 209-240. DOI: 10.1098/rstb.2009.0302.
13. L. Chen, “Progress in study on constructal theory and its applications,” Sci China, Ser E: Technol Sci, 55(3), 2012, 802–820. DOI: 10.1007/s11431-011-4701-9.
14. A. Bejan and S. Lorente, “Constructal law of design and evolution: Physics, biology, technology, and society,” J Appl Phys, 113, 2013, 151301. DOI: 10.1063/1.4798429.
15. A. Bejan, Advanced Engineering Thermodynamics, 3rd ed., Wiley, Hoboken, 2006.
16. A. Bejan and G.W. Merkx, eds., Constructal Theory of Social Dynamics, Springer, New York, 2007.
17. P. Kalason, Le Grimoire des Rois: Theorie Constructale du Changement, L’Harmattan, Paris, 2007.
18. P. Kalason, Epistemologie Constructale du Lien Cultuel, L’Harmattan, Paris, 2007.
19. A. Bejan and S. Lorente, Design with Constructal Theory, Wiley, Hoboken, 2008. DOI: 10.1002/9780470432709.
20. D. Queiros-Conde and M. Feidt, eds., Constructal Theory and Multi-Scale Geometries: Theory and Applications in Energetics, Chemical Engineering and Materials, Les Presses de L’ENSTA, Paris, 2009.
21. L. Rocha, Convection in Channels and Porous Media: Analysis, Optimization, and Constructal Design, VDM Verlag, Saarbrücken, 2009.
22. A. Bejan, S. Lorente, A.F. Miguel, and A.H. Reis, eds, Constructal Human Dynamics, Security and Sustainability, IOS Press, Amsterdam, 2009.
23. G. Lorenzini, S. Moretti, and A. Conti, Fin Shape Optimization Using Bejan’s Constructal Theory, Morgan & Claypool Publishers, San Francisco, 2011.
24. Bachta, J. Dhombres, and A. Kremer-Marietti, Trois Ètudes sur la Loi Constructale d’Adrian Bejan, L’Harmattan, Paris, 2008.
25. N. Acuña, Mindshare: Igniting Creativity and Innovation through Design Intelligence, Motion, Henderson, NV, 2012.
26. L.A.O. Rocha, S. Lorente, and A. Bejan, Constructal Law and the Unifying Principle of Design, Springer, New York, 2012. DOI: 10.1007/978-1-4614-5049-8.
27. A. Pramanick, The Nature of Motive Force, Springer, Berlin, 2014. DOI: 10.1007/978-3-642-54471-2.
28. A. H. Reis and A. Bejan, “Constructal theory of global circulation and climate,” Int J Heat Mass Transfer, 49, 2006, pp. 1857-1875. DOI: 10.1016/j.ijheatmasstransfer.2005.10.037.
29. A. Bejan, S. Ziaei and S. Lorente, “Evolution: Why all plumes and jets evolve to round cross sections,” Scientific Reports, 4, 4730; 2014. DOI: 10.1038/srep04730.
30. H.B. Callen, Thermodynamics, Wiley, New York, 1960. DOI: 10.1063/1.3057983.
31. A. Bejan, S. Lorente, B.S. Yilbas and A.Z. Sahin, “Why solidification has an S-shaped history,” Scientific Reports, 3, 1711, 2013. DOI: 10.1038/ srep01711.
32. B. Drossel, “On the relation between the second law of thermodynamics and classical and quantum mechanics,” chapter 3 in B. Falkenburg and M. Morison, eds., Why More is Different, Springer, Berlin, 2015. DOI: 10.1007/978-3-662-43911-1_3.
33. D.F. Styer, “Insight into entropy,” Am J Phys, 68 (12), 2000, 1090-1096. DOI: 10.1119/1.1287353.
34. F.L. Lambert, “Disorder—a cracked crutch for supporting entropy discussions,” J Chem Ed, 79 (2), 2002, 187-192. DOI: 10.1021/ed079p187.
35. A. Bejan, S. Lorente, “The constructal law and the thermodynamics of flow systems with configuration,” Int J Heat Mass Transfer, 47, 2004, 3203-3214. DOI: 10.1016/j.ijheatmasstransfer.2004.02.007.
36. A. Bejan, “Why university rankings do not change: education as a natural hierarchical flow architecture,” Int J Design & Nature Ecodyn, 2(4), 2007, 319-327. DOI: 10.2495/JDN-V2-N4-319-327.
37. A. Bejan, “Constructal self-organization of research: empire building versus the individual investigator,” Int J Design & Nature Ecodyn, 3(3), 2008, 177-189. DOI: 10.2495/DNE-V3-N3-177-189.
38. A. Bejan. “Two hierarchies in science: the free flow of ideas and the academy,” Int J Design & Nature Ecodyn, 4, 2009, 386-394. DOI: 10.2495/DNE-V4-N4-386-394.
39. A. Bejan, J.D. Charles and S. Lorente, “The evolution of airplanes,” J Appl Phys, 116, 2014, 044901. DOI: 10.1063/1.4886855.
40. A. Bejan, “Technology evolution, from the constructal law,” Chapter 3 in Advances in Heat Transfer, Vol. 45, 2013, pp. 183-207; E.M. Sparrow, Y.I. Cho, J.P. Abraham and J.M. Gorman, eds.; Academic Press, Burlington. DOI: 10.1063/1.4886855.
41. A. Bejan and M. R. Errera, “Technology evolution, from the constructal law: heat transfer designs,” Int J Energy Res, 2014. DOI: 10.1002/er.3262.
42. S. Kim, S. Lorente, A. Bejan, W. Miller, J. Morse, “The emergence of vascular design in three dimensions,” J Appl Phys, 103, 2008, 123511. DOI: 10.1063/1.2936919.
43. M.R. Errera and A. Bejan, “Deterministic tree networks for river drainage basins,” Fractals, 6, 1998, 245−261. DOI: 10.1142/S0218348X98000298.