Zichao Kou | Yanjun Fang*
OPEN ACCESS
Once installed, the electricity meters will face a huge variation in operating conditions, which exerts a major influence on the measuring accuracy. Thus, it is imperative to develop an effective way to estimate the errors of electricity meters in varied operating conditions. Considering the limited sample size, this paper develops a semi-supervised sparse representation (SSR) algorithm for error estimation of electricity meters with insufficient tagged samples. Each sample was considered a combination of two sub-signals, namely, the prototype dictionary P and the variation dictionary V. The prototype errors of electricity meters were taken as the P, using the Gaussian mixture model (GMM). The linear noises were sparsely characterized by the V. On this basis, the mixed tagged and untagged samples were processed in a semi-supervised manner, to obtain the nonlinear variations between the two types of samples. To verify its effectiveness, the proposed SSR algorithm was compared with other error prediction methods through four experiments on actual datasets of different sizes. The results show that our algorithm greatly outperformed the other methods in the accurate estimation of the errors of electricity meters in operating conditions. The research results provide an innovative way to onsite calibration of electricity meters.
artificial neural network (ANN), machine learning, error estimation, electricity meters
In the field of metrology, it is a research hotspot to calibrate electricity meters in an effective manner. Many different strategies have been adopted to address this concern. The necessity of accurate calibration of electricity meters is highlighted by new international guides, which call for strong applicability of measuring instruments and high traceability of the measuring methods [1-4]. With the advent of smart grids, more and more attention has been paid to the state estimation of electricity meters via distributed management systems [5]. Against this backdrop, it is imperative to develop new ways to guarantee the accuracy of electricity meters [6].
The existing approaches mainly focus on improving the measuring accuracy of electricity meters in actual operations [7]. There is no report on how to estimate the error of these instruments. The error estimation is essentially a regression and prediction problem [8]. Various techniques can be introduced to solve this problem, many of which are related to artificial intelligence (AI) [9, 10]. In fact, the emergence of the AI has brought about many effective forecast models [11, 12].
For error estimation of electric meters in actual operations, there is a particular advantage with deep learning: the algorithms are trained with real-world data, and the error is predicted by machine learning, when enough data has been obtained. In this way, it is easy to acquire useful data, and manage possible errors, which are diverse and complex [13-16].
Through the above analysis, this paper firstly investigates how changing operating conditions influence the errors of electricity meters. Next, a special artificial neural network (ANN) was designed, and used to set up an error estimation method. The contributions of this research can be summarized as follows:
(1) This paper presents a novel semi-supervised sparse representation (SSSR) algorithm to estimate the errors of electricity meters in actual operations. With known environmental parameters and certain constraints, the proposed algorithm can ascertain the measuring accuracy of electricity meters under each environment. To the best of our knowledge, this is the first attempt to apply machine learning to estimate the errors of electricity meters.
(2) The SSSR algorithm was compared with several machine learning strategies through the accuracy analysis of initial measured data. The results confirm that our algorithm can effectively estimate the errors of electricity meters in actual operations.
(3) Our algorithm enjoys great application prospect in the verification of electricity meter measurements in actual operations.
2.1 The prototype plus variation framework
Inspired by the linear addition model, each sample was considered a combination of two sub-signals, namely, the prototype dictionary P and the variation dictionary V [17-19]:
$y=\mathbf{P} \alpha+\mathbf{V} \beta+\mathbf{e}$ (1)
where, α and β are sparse vectors that select a finite number of bases from P and V, respectively; e is a small noise. The estimation of the two sparse vectors is equivalent to solving the ι1 minimization problem:
$\left[\frac{\alpha}{\beta}\right]=\underset{\alpha, \beta}{\arg \min } 22\left\|[\mathbf{P} \quad \mathbf{V}]\left[\frac{\alpha}{\beta}\right]-y\right\|_{2}^{2}+\lambda\left\|\left[\frac{\alpha}{\beta}\right]\right\|_1$ (2)
where, λ is the regularization parameter; y is a test sample. Then, the reconstruction residuals of each class can be calculated, using $\hat{\alpha}$ and $\hat{\beta}$, and the test sample y can be allocated to the class with the smallest residual [20].
In addition, the prototype dictionary P can be expressed as:
P=A (3)
$\mathbf{P}=\left[c_{1}, \ldots, c_{K}\right]$ (4)
The above formulas of P and V work well, when many tags are available. In real-world scenarios, however, the tagged training data often have a limited size, and differ greatly from the untagged testing data [21]. Therefore, it is very difficult to produce a good prototype image that distinguishes between the tagged training data and the untagged testing data.
2.2 Class centroid estimation
Considering the nonlinear variation between tagged and untagged samples, the centroid estimation of tagged and untagged data for each topic was performed to learn the prototype of each class [22].
First, the data were cleaned to eliminate the linear variation in each sample. Meanwhile, one data entry from the same model to be tested was assumed to obey Gaussian distribution. The data cleaning was completed by solving (1) by (5) or (6) for the P, and solving (1) by (3) or (4) for the V:
$\hat{\mathbf{y}}=\mathbf{y}-\mathbf{V} \hat{\beta}=\mathbf{P} \hat{\alpha}+\mathbf{e}$ (5)
where, $\hat{\mathbf{y}}$ is the rectified untagged image without linear variation; $\hat{\alpha}$ and $\hat{\beta}$ can be initialized by $(2) .$ Then, the problem is converted to finding the relationship between the rectified untagged data $\hat{\mathbf{y}}$ and the centroid of its class.
The sparsity coefficient α is so sparse that each class is usually represented by only one P. For untagged sample y, the most important entry for P was selected by $\mathbf{P} \hat{\alpha}$, i.e. the centroid of the closest class to $\hat{\mathbf{y}}$. However, the class centroid thus selected cannot be directly used as the initial class centroid of the Gaussian distribution [23]. This is because the largest element of α rarely equals one. In other words, the $\mathbf{P} \hat{\alpha}$ often produces an extra small noise-like class centroid. Suppose the most important entry of α is associated with class i, we have:
$P \hat{\alpha}=P[\varepsilon, \varepsilon, \ldots, s(\text { ith entry }), \ldots, \varepsilon]^{T}=s \mathbf{a}_{i}^{*}+\mathbf{P} \hat{\boldsymbol{a}}_{i}^{-}=s \mathbf{a}_{i}^{*}+e^{\prime}$ (6)
where, $\quad$ the $\quad$ sparsity $\quad$ coefficient $\hat{\alpha}=[\varepsilon, \varepsilon, \ldots, s(i t h \quad \text { entry }), \ldots, \varepsilon]^{T} \quad$ consists of the small value and the effective values the scale parameter $s$ in the $i$ -th entry; $\boldsymbol{a}_{i}^{*}$ is the i-th column of $\mathrm{P}; \mathbf{e}=\mathbf{P} \hat{\alpha}_{i}$ is the sum of all noise-like class centroids selected by $\hat{\alpha}_{i},$ which contains only small values that complement the $\hat{\alpha}$.
In the preceding subsection, the prototype dictionary P has been normalized by (2) into a second-order norm. Similarly, the scale parameter s can be eliminated by normalizing $\mathbf{y}-\mathbf{V} \hat{\beta}$ into a second-order norm:
$\hat{\mathbf{y}}^{n o r m}=\operatorname{norm}(\mathbf{y}-\mathbf{V} \hat{\beta})=\operatorname{norm}\left(s \boldsymbol{a}^{*}+\mathbf{e}^{\prime}+\mathbf{e}\right) \approx \boldsymbol{a}_{i}^{*}+\mathbf{e}^{*}$ (7)
where, $e^{*}$ is a small noise obeying zero-mean Gaussian distribution. Because of the small sample size from each class, the Gaussian noise was assigned differently to each class, i.e. $e_{i}^{*}=\mathrm{N}(0, \mathrm{i}),$ aiming to improve the estimation accuracy of the P. The normalized y^ obeys the following distribution:
$\hat{\boldsymbol{y}}^{n o r m} \approx \boldsymbol{a}_{i}^{*}+\mathbf{e}_{i}^{*} \in N\left(\boldsymbol{a}_{i}^{*}, \Sigma_{i}\right)$ (8)
2.3 Algorithm design
The SSSR algorithm was summarized as Algorithm 1 below. Besides the regularization parameter λ, the inputs of the algorithm fall into the following categories:
(1) Considering the small size of training samples, a set of tagged and untagged images D={(y1, l1) ..., (yn, ln), yn+1, ..., yN}, where yi∈RD, i=1, …, N are image vectors, and li, i=1, …, n are the tags, and the number of tagged images in each class ni were inputted to the algorithm.
(2) Considering the sparse least-squares prediction problem (SLSPP), a set of prototype and testing images D={(y1, 1), ..., (yK, K), yK+1, ..., yN }, where T={y1, ..., yK} is the prototype set with SLSPP, and 1, …, K are the tags, and a tagged generic dataset with N g samples from K g subjects, G={G1, ..., GN g } were inputted to the algorithm.
This section attempts to compare the performance of the proposed method with other error prediction methods. Several experiments were carried out on Google’s TensorFlow framework, using Python codes and actual measured datasets. The dataset size varies from experiment to experiment.
|
Algorithm 1 The SSSR algorithm |
|
|
1 |
Compute the prototype matrix, P, by (6) to overcome the limited sample size. |
|
2 |
Compute the universal linear variation matrix, V, by (4) to overcome the limited sample size. |
|
3 |
Perform dimensional reduction (e.g. principal component analysis) on the whole dataset as well as P and V, and then normalize them into second-order $\ell^{2}$ norm. |
|
4 |
Solve the sparse representation problem to estimate $\hat{\alpha}$ and $\hat{\beta}$ for all the untagged y by (2). |
|
5 |
Rectify the samples to eliminate linear variation and normalize them as $\ell^{2}$-norms. |
|
6 |
Initialize each Gaussian distribution of the Gaussian mixture matrix (GMM) by $N\left(\mathbf{p}_{i}, \mathbf{I}\right)$ for $i=1, \ldots, K$ where $\mathbf{p}_{i}$ is the $i$ -th column of $P .$ |
|
7 |
Initialize the prior of the GMM, $\pi_{i}=n_{i} / n$. |
|
8 |
Repeat the following two steps |
|
9 |
E-Step: Calculate $\hat{Z}_{i j}$ by (3) and (4). |
|
10 |
M-Step: Optimize the model parameter $\theta=\left\{\mu_{j}, \Sigma_{j}, \pi_{j}, \text { for } j=1, \ldots, K\right\}$ |
|
11 |
until satisfy (8). |
|
12 |
Let $\mathbf{P}^{*}=\left[\hat{\mu}_{1}, \ldots, \hat{\mu}_{K}\right]$ and estimate $\hat{\alpha} *$ and $\hat{\beta} *$ by (2). |
|
13 |
Compute the residual rk(y) by (8). |
|
14 |
Output: Tag(y)=arg minkrk(y). |
Three metrics, namely, the mean absolute error (MAE), the mean squared error (MSE) and the root mean square error (RMSE), were selected to evaluate the prediction results from different angles. The MAE is the most robust metric of the deviation between the real value and the predicted value [24], especially for large errors. The MSE and the RMSE can effectively characterize the dispersion of each method [25]. However, the squaring operation makes the two metrics more sensitive to large errors, which may lead to error magnification.
The MAE, MSE and RMSE can be respectively calculated by:
$M A E=\frac{1}{n} \sum_{i=1}^{n}\left|y_{i}-y_{i}^{\prime}\right|$ (9)
$M S E=\frac{1}{n} \sum_{i=1}^{n}\left(y_{i}-y_{i}^{\prime}\right)^2$ (10)
$R M S E=\sqrt{\frac{1}{n} \sum_{i=1}^{n}\left(y_{i}-y_{i}^{\prime}\right)}$ (11)
where, n is the sample size; yi is the real value; y'i is the predicted value.
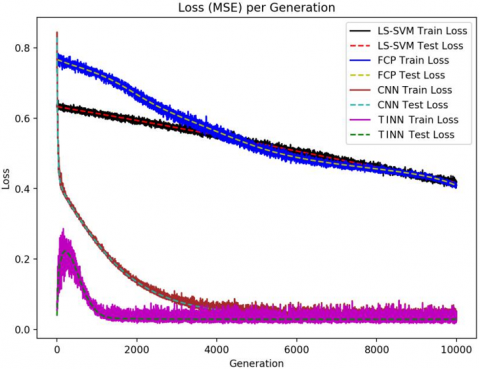
Using the most effective hyperparameters, the proposed SSSR algorithm was compared with the least squares support vector machine (LS-SVM), the fully-connected multi-layer perceptron (FCP) and the convolutional neural network (CNN). The same dataset was adopted to train the four methods. Figure 1 and Table 1 compare the prediction of each method with the actual value.
Figure 1. Prediction errors of all four methods
In general, the SSSR algorithm achieved the best performance in error prediction, judging by all three metrics. By contrast, the LS-SVM and the FCP were outperformed by a significant margin. The results prove that the SSSR algorithm can predict errors accurately based on the specific environmental parameters, and provide an excellent solution to error estimation despite the variation in environmental conditions.
Table 1. Performance comparison of the four methods
$\begin{array}{cccc}\hline \text { Method } & {\mathrm{MSE}} & {\mathrm{MAE}} & {\mathrm{RMSE}} \\ \hline \text { LS-SVM } & {0.175321} & {0.324835} & {0.418713} \\ {\mathrm{FCP}} & {0.167789} & {0.288262} & {0.409621} \\ {\mathrm{CNN}} & {0.00262098} & {0.0360277} & {0.0511955} \\ {\mathrm{SSSR}} & {0.00235818} & {0.0101225} & {0.0485611} \\ \hline\end{array}$
The error prediction effect can also be measured by the computing time in the training phase. Compared with the three contrastive methods, especially, the LS-SVM, the proposed SSSR algorithm consumed a very short amount of time in the training phase. Therefore, our algorithm outshines the other methods in the error estimation of electricity meters.
According to relevant standards on the calibration of electricity meters, the predicted error should be two orders of magnitude higher than the measured error. Therefore, prediction error in our experiments must fall within 1%. With a prediction error of only 0.002%, the proposed SSSR algorithm clearly satisfies this requirement, and applies to onsite calibration of electricity meters.
Admittedly, any neural network faces a high initial overhead, due to necessity of repeated training. However, the experimental results demonstrate that the SSSR algorithm overcomes this defect and realizes a very high accuracy in the error estimation of electricity meters under varied conditions. As long as there are enough training data, a huge amount of time will be saved through machine learning.The error prediction effect can also be measured by the computing time in the training phase. Compared with the three contrastive methods, especially, the LS-SVM, the proposed SSSR algorithm consumed a very short amount of time in the training phase. Therefore, our algorithm outshines the other methods in the error estimation of electricity meters.
This paper applies deep learning to error prediction of electricity meters in operating conditions. The SSSR algorithm was developed to model the linear and nonlinear variations between tagged training samples and untagged testing samples. To improve the classification accuracy, a more precise prototype dictionary P was prepared to characterize the most prominent features of each topic. The proposed algorithm was compared through experiments on real-world datasets with several popular methods for error estimation. The comparison shows that: the proposed algorithm greatly improved the error prediction results, facing the limited number of training samples and the SLSPP problem. In future research, the SSSR algorithm will be combined with dictionary learning methods to further improve its performance, and improve the prototype dictionary by strategies other than the GMM.
[1] Muscas, C., Pau, M., Pegoraro, P.A., Sulis, S. (2015). Smart electric energy measurements in power distribution grids. IEEE Instrumentation and Measurement Magazine, 18(1): 17-21. http://dx.doi.org/10.1109/MIM.2015.7016676
[2] Wang, X., Wang, J., Yuan, R., Jiang, Z. (2019). Dynamic error testing method of electricity meters by a pseudo random distorted test signal. Applied Energy, 249: 67-78. https://doi.org/10.1016/j.apenergy.2019.04.054
[3] Brandolini, A., Faifer, M., Ottoboni, R. (2009). A simple method for the calibration of traditional and electronic measurement current and voltage transformers. IEEE Transactions on Instrumentation and Measurement, 58(5): 1345-1353. http://dx.doi.org/10.1109/TIM.2008.2009184
[4] Femine, A.D., Gallo, D., Landi, C., Luiso, M. (2009). Advanced instrument for field calibration of electrical energy meters. IEEE Transactions on Instrumentation and Measurement, 58(3): 618-625. http://dx.doi.org/10.1109/TIM.2008.2005079
[5] Mazza, P., Bosonetto, D., Cherbaucich, C., De Donà, G., Franchi, M., Gamba, G., Gamba, G., Gentili, M., Milanello, C.D. (2014). On- site verification and improvement of the accuracy of voltage, current and energy measurements with live-line working methods: New equipment, laboratory and field experience, perspectives. 2014 11th International Conference on Live Maintenance (ICOLIM), 1-8. http://dx.doi.org/10.1109/ICOLIM.2014.6934377
[6] Granderson, J., Touzani, S., Custodio, C., Sohn, M.D., Jump, D., Fernandes, S. (2016). Accuracy of automated measurement and verification (M&V) techniques for energy savings in commercial buildings. Applied Energy, 173: 296-308. https://doi.org/10.1016/j.apenergy.2016.04.049
[7] Femine, A.D., Member, S., Gallo, D., Landi, C., Luiso, M. (2007). Measurement equipment for on-site calibration of energy meters. 2007 IEEE Instrumentation & Measurement Technology Conference, 975-980. http://dx.doi.org/10.1109/IMTC.2007.379144
[8] Avram, S., Plotenco, V., Paven, L.N. (2017). Design and development of an electricity meter test equipment. 2017 International Conference on Optimization of Electrical and Electronic Equipment (OPTIM) & 2017 Intl Aegean Conference on Electrical Machines and Power Electronics (ACEMP), 96-101. http://dx.doi.org/10.1109/OPTIM.2017.7974954
[9] Zhou, N.C., Wang, J., Wang, Q.G. (2017). A novel estimation method of metering errors of electric energy based on membership cloud and dynamic time warping. IEEE Transactions on Smart Grid, 8(3): 1318-1329. http://dx.doi.org/10.1109/TSG.2016.2619375
[10] Berriel, R.F., Lopes, A.T., Rodrigues, A., Varejão, F.M. Oliveira-Santos, T. (2017). Monthly energy consumption forecast: A deep learning approach. 2017 International Joint Conference on Neural Networks (IJCNN), 4283-4290. http://dx.doi.org/10.1109/IJCNN.2017.7966398
[11] Dong, B., Li, Z.X., Rahman, S.M., Vega, R., (2016). A hybrid model approach for forecasting future residential electricity consumption. Energy and Buildings, 117: 341-351. https://doi.org/10.1016/j.enbuild.2015.09.033
[12] Daut, M.A.M., Hassan, M.Y., Abdullah, H., Rahman, H. A., Abdullah, M.P., Hussin, F. (2017). Building electrical energy consumption forecasting analysis using conventional and artificial intelligence methods: A review. Renewable and Sustainable Energy Reviews, 70: 1108-1118. https://doi.org/10.1016/j.rser.2016.12.015
[13] Lecun, Y., Bengio, Y., Hinton, G. (2015). Deep learning. Nature, 521(7553): 436-444. http://dx.doi.org/10.1038/nature14539
[14] Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61: 85-117. http://dx.doi.org/10.1016/j.neunet.2014.09.003
[15] Liu, W.B., Wang, Z.D., Liu, X.H., Zeng, N.Y., Liu, Y.R., Alsaadi, F.E. (2017). A survey of deep neural network architectures and their applications. Neurocomputing, 234: 11-26. https://doi.org/10.1016/j.neucom.2016.12.038
[16] Szegedy, C., Liu, W., Jia, Y.Q., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A. (2015). Going deeper with convolutions. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1-9. http://dx.doi.org/10.1109/CVPR.2015.7298594
[17] Montavon, G., Samek, W., Müller, K.R., (2018). Methods for interpreting and understanding deep neural networks. Digital Signal Processing, 73: 1-15. https://doi.org/10.1016/j.dsp.2017.10.011
[18] Montavon, G., Lapuschkin, S., Binder, A., Samek, W., Müller, K.R. (2017). Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognition, 65: 211-222. https://doi.org/10.1016/j.patcog.2016.11.008
[19] Shelhamer, E., Long, J., Darrell, T. (2017). Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(4): 640-651. http://dx.doi.org/10.1109/TPAMI.2016.2572683
[20] Ordóñez, F., Roggen, D. (2016). Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors, 16(1): 115-139. https://doi.org/10.3390/s16010115
[21] Carstens, H., Xia, X.H., Yadavalli, S. (2018). Bayesian energy measurement and verification analysis. Energies 11(2): 380-399. https://doi.org/10.3390/en11020380
[22] Boras, V., Tackovic, K., Plestina, V. (2016). Expression of uncertainty in measurements of active power by means of electrodynamic wattmeter. Tehnicki Vjesnik-Technical Gazette, 23(6): 1813-1820. https://doi.org/10.17559/TV-20150928102715
[23] Kaczmarek, M. (2016). Measurement error of non-sinusoidal electrical power and energy caused by instrument transformers. IET Generation, Transmission & Distribution, 10(14): 3492-3498. http://dx.doi.org/10.1049/iet-gtd.2016.0131
[24] Park, S.J., Lim, S.K., Park, S.M. (2019). High-speed remote power measurement by communication of the maximum and minimum measurement value. Wireless Personal Communications, 105(2): 491-507. https://doi.org/10.1007/s11277-018-6082-x
[25] Schneider, S.M., Sayago, J., Centner, M., Plath, R., Schäfer, U. (2017). Measurement uncertainty of power measurement on inverter-fed drives in the medium voltage range. e & i Elektrotechnik und Informationstechnik, 134(2): 203-211. https://doi.org/10.1007/s00502-017-0496-0