Zimao Peng
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The operation and maintenance (O&M) of intelligent building information model (IBIM), as an important aspect of modern building informatization, plays a critical role in the construction of smart cities and the renovation of modern buildings. Due to the complex structure and sheer size of IBIM data, the O&M system of IBIM faces a huge workload and a high cost. Based on cloud computing, this paper proposes an O&M strategy for IBIM data, which meets the needs for stable management of massive data, enables three-dimensional (3D) collaborative visualization of building information model (BIM), improves the efficiency of data storage, scheduling, and O&M. Firstly, the basic structure of IBIM data was standardized according to The Industry Foundation Classes (IFC) (ISO 16739-1:2018). Then, the features were sampled from the standardized IBIM cloud data. After that, the storage data were subject to routing, coding, matching feature compression, and adaptive attribute clustering. On this basis, an optimization model was established for the storage structure of IBIM cloud data. Finally, a batch feature extraction method was designed for 3D structure distribution of job-based 3D cloud storage model. The proposed strategy was proved effective through experiments. The research results provide a reference for applying 3D cloud storage model in other fields.
intelligent building information model (IBIM), cloud computing, the industry foundation classes (IFC), MapReduce environment
Building information modeling is a technology that integrates various building-related information into an information database of three-dimensional (3D) models. The core of the technology is to provide a complete and realistic information library for virtual 3D models in constructional engineering [1-5]. The cloud data of intelligent building information model (IBIM) need to be operated and maintained to analyze the model features and reconstruct the model. The operation and maintenance (O&M) require the integration of advanced technologies into the lifecycle data of the building, including cloud computing, the Internet, and the Internet of things (IoT). The integrated strategy boasts great application potential in such fields as building structure drawing, intelligent building renovation and reuse, intelligent management of electrical equipment, and 3D collaborative visualization [6-10].
Fruitful results have been achieved on the storage design of 3D cloud data. In general, the 3D cloud data are stored using artificial neural network (ANN), wavelet analysis, statistical feature analysis, and empirical mode decomposition (EMD) [11-14]. Wang et al. [15] expounded the principle and technical features of neural network (NN)-based feature extraction from 3D point cloud data collected by laser scans, and summarized its application advantages in the construction of smart cities. Anagnostopoulos et al. [16] sorts out and evaluates the fineness of the division of BIM cloud data for different purposes, optimized the evaluation indies and weights through wavelet analysis, and realized the intelligent analysis on the division scheme.
The modelling of IBIM cloud data is the basis for optimizing the data collection and management of 3D models. The relevant research mainly focuses on the reverse engineering of BIM from point cloud, as well as the virtual reconstruction and simulation of existing buildings [17-20]. Based on point cloud technology, Ma et al. [21] developed an automatic O&M method for datacenters, which excels in anti-interference and data storage. McNally et al. [22] detailed the processing steps and algorithms of point cloud data in reconstructing ancient building models, and imported the reverse engineered BIM into the web geographic information system (GIS) platform of ArcGIS, providing an effectively way to rendering largescale GIS data, while meeting the accuracy of building description.
Apart from being massive and diverse, the IBIM cloud data are often disturbed by multidisciplinary O&M information during the collection and storage processes. As a result, it takes a long time to discover, judge, and handle the needs for storage and scheduling of these data, which reduces the O&M efficiency.
To solve the problem, this paper proposes an O&M strategy for IBIM data based on cloud computing. Firstly, the basic structure of IBIM data was standardized according to The Industry Foundation Classes (IFC) (ISO 16739-1:2018), and the design and realization steps of standardization sub-models were explained. Next, the features were sampled from the standardized IBIM cloud data, and used to rationalize the storage method for the data. After that, the storage data were subject to routing, coding, matching feature compression, and adaptive attribute clustering, and an optimization model was established for the storage structure of IBIM cloud data. Finally, a batch feature extraction method was designed for 3D structure distribution of job-based 3D cloud storage model, and a complete O&M strategy for IBIM data was presented under the MapReduce environment. The proposed strategy was proved effective through experiments.
With the advancement of centralized information processing, the O&M of BIM data in the environment of cloud computing has witnessed breakthroughs in various aspects, including but not limited to data collection, data labeling, data induction, data analysis, and data processing.
Drawing on the Code for Design of Intelligent Buildings (GB50314-2015), the IBIM data can be operated and maintained in a scientific, precise, and efficient manner by introducing information technology to tasks like the simulation of data input and output and the calculation of evaluation indices.
The data structure of BIM is highly scalable, because the 3D BIMs contain the lifecycle information of construction projects. To make digital evaluation of intelligent buildings, it is necessary to digitize the intelligent building information, and add the digitized information to the IFC framework.
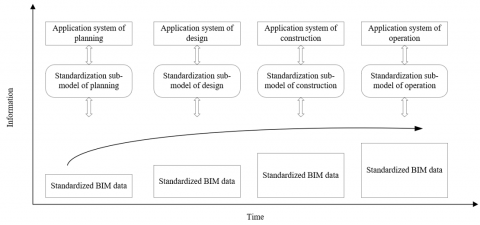
Figure 1. The standardization of IBIM data structure
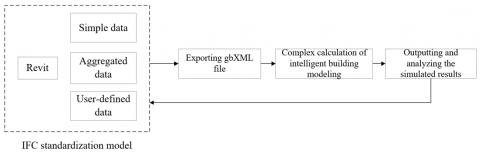
Figure 2. The workflow of intelligent building data exchange
As shown in Figure 1, the IBIM data structure was standardized in four phases, namely, planning, design, construction, and operation of the intelligent building. In each phase, a standardization sub-model was constructed according to the specific application needs. Through the four phases, the BIM data were gradually standardized, producing a set of standardized IFC engineering information covering the lifecycle of the intelligent building.
Each standardization sub-model was designed and implemented in three steps:
Step 1. Define the basic BIM data corresponding to the basic types under the IFC, using the simple data type in C++.
Step 2. Define the basic BIM data corresponding to the LIST of aggregated type under the IFC, using the Standard Template Library (STL) list of C++.
Step 3. Directly use the basic BIM data corresponding to the user-defined type under the IFC.
Taking Revit as an example, Figure 2 provides the intelligent building data exchange process for the data items to be standardized as per the Code for Design of Intelligent Buildings (GB50314-2015). It can be seen that the closed-loop exchange between BIM data and intelligent building simulation data can be realized by importing the input and output of the simulation data into the gbXML file.
In the environment of cloud computing, it is a complex task to collect and store IBIM cloud data, which greatly affects the design of a rational O&M strategy. In this section, the features are sampled from the standardized IBIM cloud data, and used to determine the suitable storage method for different types of standardized data.
Firstly, the distributed IBIM cloud data in the feature space were described as a dataset U={u1, u2, …, uM}. Then, semantic ontology and directed graph were adopted to model the storage system of distributed IBIM cloud data, and collect the feature points of nodes A and B on the 3D platform, where the IBIM cloud data are distributed. Let relational models R(A) and R(B), (a, b) be a pair of named anchors of A and B. To create a rational IBIM cloud data collection model, the data transmission channel was expressed by the number of hops d×L, SN, and sink.
Suppose the directed graph of the 3D platform satisfies edge (c, d)∈E, node A⊂U, B⊂U, and A∩B=φ. Then, the fuzzy point set was extracted from the 3D phase space of IBIM cloud data series. During the extraction, the data types were matched and the semantic orientation features were analyzed through cloud computing servers. Let Δt be the time interval of cloud data collection. Then, the time series of IBIM cloud data collection can be established as UT={u(t0), u(t0+Δt), …, u(t0+iΔt), …, u(t0+LΔt)}, where L is the vector length of cloud data information flow. Let ROL and N be the time window function and dimensionality of the 3D phase space, respectively. Based on the Takens’ Embedding theorem, the state vector of the output from the collection of IBIM cloud data can be expressed as:
${{U}_{T}}=\left[ \begin{align} & \text{ }u({{t}_{0}})\text{ }u({{t}_{0}}+\Delta t)\text{ }\cdots \text{ }u({{t}_{0}}+L \Delta \text{t) } \\ & u({{t}_{0}}+ROL\cdot \Delta t)\text{ }u\left( {{t}_{0}}+(ROL+1)\Delta t \right)\text{ }\cdots \text{ }u({{t}_{0}}+L\Delta t+ROL\cdot \Delta t) \\ & \text{ }\vdots \text{ }\vdots \text{ }\vdots \\ & u({{t}_{0}}+ROL\cdot (N-1)\Delta t)\text{ }u\left[ {{t}_{0}}+\left( 1+ROL\cdot (N-1) \right)\Delta t \right]\text{ }\cdots \text{ }u\left[ {{t}_{0}}+\left( L+ROL\cdot (N-1) \right)\Delta t \right]\text{ } \\ \end{align} \right]$ (1)
The collection and analysis results of IBIM cloud data were imported to the cloud data storage model as the input information stream. Then, a suitable storage method was selected for the collected IBIM cloud data. In this paper, the storage structure of IBIM cloud data is constructed through nonlinear time series analysis. The collected IBIM cloud data can be described as the following information flow time series model:
$s(t)=\sum\limits_{m=1}^{M}{\sum\limits_{n=0}^{N-1}{{{V}_{e-mn}}(t)}}{{f}_{d-mn}}(t)+\varepsilon (t)$ (2)
where, Ve-mn(t) is the envelope function of the IBIM cloud data information flow; fd-mn(t) is the Doppler frequency shift of IBIM cloud data; ε(t) is a disturbance term.
To adapt the IBIM cloud data storage medium to the wide and stable distribution of IFC standard data structure, the logical relationship between the storage nodes in the IBIM cloud data can be illustrated by the following multivariable autoregressive model:
$F={{B}_{a}}a+{{B}_{b}}b+{{B}_{c}}c+{{B}_{d}}d$ (3)
where, Ba, Bb, Bc, and Bd are parameters whose sum equals 1; a is the storage quality coefficient of IBIM cloud data; b is the data security evaluation coefficient; c is the scheduling time for storage and access of IBIM cloud data; d is the storage cost of IBIM cloud data.
4.1 Network coding of storage data
To ensure the network throughput, robustness, and security of data transmission, the IBIM cloud data must be subject to information exchange (i.e. routing and coding) before being uploaded to the storage nodes.
Firstly, the IBIM cloud data were preprocessed through linear coding. The original dataset U={u1, u2, …, uM} in the feature space was decomposed into V data blocks, namely, Ui=[ui1, ui2, …, uiV]. The vectors of the data blocks can be expressed as:
$U=\left[ \begin{matrix} {{u}_{11}} & {{u}_{12}} & \cdots & {{u}_{1V}} \\ {{u}_{21}} & {{u}_{22}} & \cdots & {{u}_{2V}} \\ \vdots & \vdots & {} & \vdots \\ {{u}_{M1}} & {{u}_{M2}} & \cdots & {{u}_{MV}} \\\end{matrix} \right]$ (4)
It is assumed that the encoded data packets can be represented by a matrix O:
$O=\left[ \begin{matrix} {{y}_{11}} & {{y}_{12}} & \cdots & {{x}_{1V}} \\ {{y}_{21}} & {{x}_{22}} & \cdots & {{y}_{2V}} \\ \vdots & \vdots & {} & \vdots \\ {{y}_{W1}} & {{x}_{W2}} & \cdots & {{x}_{WV}} \\\end{matrix} \right]$ (5)
where, W is the number of encoded data packets. During the U→O coding, the coding coefficient matrix defined by the user Tcus and that generated randomly by the system Tran can be respectively expressed as:
${{T}_{cus}}=\left( \begin{matrix} {{\sigma }_{11}} & {{\sigma }_{12}} & \cdots & {{\sigma }_{1M}} \\ {{\sigma }_{21}} & {{\sigma }_{22}} & \cdots & {{\sigma }_{2M}} \\ \vdots & \vdots & {} & \vdots \\ {{\sigma }_{K1}} & {{\sigma }_{K2}} & \cdots & {{\sigma }_{KM}} \\\end{matrix} \right)$ (6)
${{T}_{ran}}=\left( \begin{matrix} {{\tau }_{11}} & {{\tau }_{12}} & \cdots & {{\tau }_{1M}} \\ {{\tau }_{21}} & {{\tau }_{22}} & \cdots & {{\tau }_{2M}} \\ \vdots & \vdots & {} & \vdots \\ {{\tau }_{W1}} & {{\tau }_{W2}} & \cdots & {{\tau }_{WM}} \\\end{matrix} \right)$ (7)
After coding, the original dataset was transformed into W coded data packets containing WM data blocks. Figure 3 presents the 3D cloud storage model for IBIM cloud data. The model was constructed in the following steps:
Step 1. Select the reference surface S1 of the 3D IBIM platform; randomly choose WM/2 data blocks, and store them on the s nodes of S1 in the form of vectors (each node is allocated WM/2s data blocks).
Step 2. Build a 3D cloud storage model for the BIM of an intelligent building as shown in Figure 3; store the remaining WM/2 data blocks as vectors on the s nodes of S2, the plane opposite to S1.
Step 3. Randomly select two sets of WM/4 data blocks from the WM/2 data blocks stored on S1 and S2, respectively, and store them on the s nodes of S3; store the remaining two sets on the s nodes of S4.
Step 4. Randomly select two sets of WM/4 data blocks from the data blocks stored on S1 and S3, respectively, and store them on the s nodes of S5; Randomly select two sets of WM/4 data blocks from the data blocks stored on S2 and S4, respectively, and store them on the s nodes of S6.
Figure 3. The 3D cloud storage model of IBIM cloud data
4.2 Storage structure optimization model
To minimize the storage cost and improve storage security, the IBIM cloud data need to be reorganized and matched. In this paper, the data are subject to matching feature compression and adaptive attribute clustering, during the data block generation of the 3D cloud storage model. The information flow (2) of IBIM cloud data was mapped to the 3D cloud storage model, via phase space reconstruction. Let h be the spectral feature of the 3D cloud storage model. Then, the reconstructed phase space can be described as:
$\Gamma [u(t)]=h(\lambda -g\sin \theta ){{e}^{-jg\sin \theta (\frac{g}{2}\cos \theta -\lambda )}}$ (8)
where, λ is the characteristic scale of the data stored in the 3D cloud storage model; h is the Doppler spectral feature; g is the frequency-domain orthogonal function of the fractional Fourier transform. After the removal of redundant data and filtering, the cloud data can go through the matching feature compression:
$h(t)=\sum\limits_{i=0}^{M}{\sum\limits_{j=0}^{V}{{{A}_{ij}}{{e}^{j{{\theta }_{i}}(t)}}\delta (t-i\Delta t)}}$ (9)
where, δ(t-iΔt) is the impulse response function; Aij is the volume of data packet(s). The data features were matched through the optimization of the target basis function, according to the criteria for removing redundant data in matching feature compression. Let fd-sk be the k-th reference surface in the 3D cloud storage model, and tcen be the time interval of storing the data on the reference surface. Then, the compressed data packet can be expressed as:
${{f}_{d-3D}}=\sum\limits_{k=1}^{6}{[{{f}_{d-sk}}},{{t}_{cen}}]{{t}_{cen}}$ (10)
To realize IFC standardization of the storage data, fuzzy C-means (FCM) algorithm was employed to cluster the cloud data under the IFC, after the completion of matching feature compression. Through the clustering, four clusters Φa, Φb, Φc, and Φd were created for the IBIM cloud data, reflecting the clustering attributes of storage quality, security, scheduling time, and storage cost, respectively. The output function of the FCM algorithm can be defined as:
$\begin{align} & J={{\omega }_{a}}\sum\limits_{l=1}^{W\times M}{({{M}_{a-l}}}-{{H}_{l}})+{{\omega }_{b}}\sum\limits_{l=1}^{W\times M}{({{M}_{b-l}}}-{{H}_{l}}) \\ & \text{ }+{{\omega }_{c}}\sum\limits_{l=1}^{W\times M}{({{M}_{c-l}}}-{{H}_{l}})+{{\omega }_{d}}\sum\limits_{l=1}^{W\times M}{({{M}_{d-l}}}-{{H}_{l}}) \\ \end{align}$ (11)
where, ωa, ωb, ωc, and ωd are the weight coefficients of storage quality, security, scheduling time, and storage cost, respectively. Feature attribute clustering was performed after the features Vl of clustering attributes had been generated from the data block(s). The set of clusters for the data stored in the 3D cloud storage model can be expressed as:
$C=\{{{c}_{1}},{{c}_{2}},\cdots {{c}_{k}}\}$ (12)
The MapReduce procedure needs to be updated based on the features of the standardized model structure, before mapping the operations of the 3D cloud storage model for IBIM data to MapReduce. MapReduce generally implements disordered and uniform batch processing of data blocks through five steps: FileSplit, Map, Partition, Combine and Reduce. However, the Map operation will break the fixed position of data blocks, whose formats are obj., off., etc., in the 3D cloud storage model. In such data blocks, the vertex position index indicates that the position of the data block cannot be changed.
To overcome the problem, this paper proposes a batch feature extraction method based on the 3D structure distribution of the job-based 3D cloud storage model. Firstly, all data blocks of the model were standardized and randomly sampled. Then, the spacing between the sampling points was calculated. Further, the statistics on the 3D structure distribution of the sampling points were fitted into the eigenvectors belonging to the 3D cloud storage model.
In addition, the structure of the 3D cloud storage model should be complete in the MapReduce environment, such that the data blocks of the same model, which has been disrupted by the Map operation, could be processed in the same Reduce operation. For this purpose, a triple (w, RS, D) was designed based on data packet(s) for the model, plus the corresponding completeness preservation function H(w, RS, D), where w is the serial number of data packet; RS is the serial number of reference surface; D is the distance from the center of the reference surface to the starting position.
5.1 Job 1: Standardization of model data
In the Hadoop environment, the IBIM data in the 3D cloud storage model can be standardized in three steps:
Step 1. In the Map operation, read all the data blocks of the 3D cloud storage model, and output the triples corresponding to these data blocks.
Step 2. Construct the model completeness preservation function, allocate the data blocks with the same start into the same group, and rank the data blocks processed in the same Reduce operation by the triple.
Step 3. In the Reduce operation, obtain the reference surface from the triplet, derive the center coordinates of the 3D cloud storage model from those of the reference surface, and normalize the data packets in each group, that is, normalize the data of the 3D cloud storage model to the unit circle; Finally, output the normalized data.
5.2 Job 2: Random sampling of model data
In the Hadoop environment, the IBIM data in the 3D cloud storage model can be randomly sampled in three steps:
Step 1. In the Map operation, create Double variables for the simple data type, aggregated data type, and user-defined type under the IFC standard, and output them with the triples.
Step 2. Group the data blocks with the same start, using the model completeness preservation function, and rank the data blocks processed in the same Reduce operation by the triple.
Step 3. In the Reduce operation, obtain the total data size of the 3D cloud storage model from the triples, conduct area-weighted random sampling of the data stored on reference surfaces, and output the sampled data.
5.3 Job 3: Eigenvector extraction from model data
In the Hadoop environment, the eigenvectors can be extracted from the IBIM data in the 3D cloud storage model in two steps:
Step 1. In the Map operation, read the output data of Job 1 and convert them into Text type variables, and process the sampling points of the same mode in the same Reduce operation.
Step 2. In the Reduce operation, calculate the Euclidean distance between sampling points, generate a distance histogram based on the statistics of the Euclidean distances, fit the statistical results, extract the eigenvectors of dim number, and output them as the eigenvectors of the model.
Several experiments were carried out to test the storage performance of the proposed 3D cloud storage model for IBIM cloud data in the Hadoop environment.
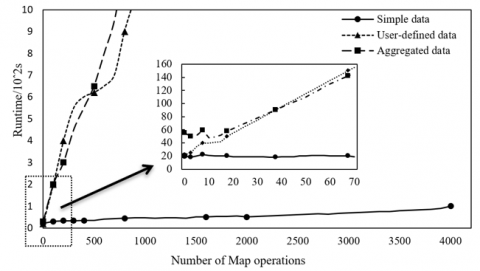
The 73MB IBIM cloud dataset was taken from the test set as the object of the experiments. The simple type, aggregated type, and user-defined type of the IFC standard were separately used as the input format of MapReduce. Each type of data was segmented by the corresponding method, before being used to test the effects of the data type on the job of batch feature extraction in Map operation.
As shown in Figure 4, with the growing number of Map operations, the job durations of simple data and user-defined data both surged up, while the job duration of aggregated data did not increase substantially. The reason is that the Hadoop distributed file system (HDFS) frequently reads and writes numerous small data packets, extending the job duration. For the aggregated data, the FCM clustering greatly shortens the start time of task. The time-saving effect of the FCM offsets the time extension induced by the growing number of Map operations.
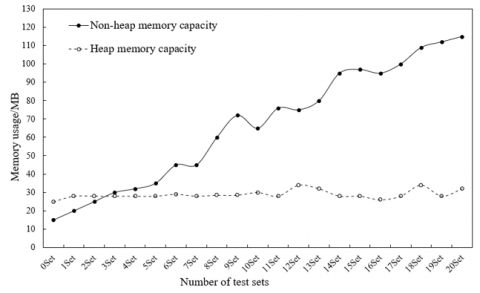
Figure 5 shows the variation in memory usage of storage nodes with the expansion of the test set. It can be seen that, with the increase of storage capacity, the heap memory capacity gradually increased, while the non-heap memory capacity fluctuated less significantly.
Figure 4. The influence of the number of Map operations on the job of batch feature extraction
Figure 5. The variation in memory usage of storage nodes with the expansion of the test set
Figure 6. The memory usages of storage nodes with and without matching feature compression
To disclose the effects of network coding and matching feature compression on memory usage, the storage nodes in 3D cloud storage model were compared in terms of the compression degree. Figure 6 compares the memory usages of storage nodes with and without matching feature compression during the data block generation. Obviously, the matching feature compression reduced the information scale of the metadata in data packets, thereby lowering the memory usage of storage nodes.
To verify the effectiveness of the job-based batch feature extraction for IBIM data, twenty 3D cloud storage models with different data volumes were selected from the test set, creating a sub-test set. The corresponding MapReduce program was developed to process the sub-test set. The job durations of each model were recorded and plotted into curves (Figure 7). It can be seen that the job duration decreased with the data volume, and increased significantly with the rise of data volume.
Figure 7. The job durations of each 3D cloud storage model
This paper designs an O&M strategy for IBIM data based on cloud computing. Firstly, the basic structure of IBIM data was standardized under the IFC, and the design and implementation of standardization sub-models were illustrated in details. The IFC standardization was proved effective through experiments on how the number of Map operations affect the job of batch feature extraction, in which the MapReduce inputs are in the formats of simple data, aggregated data, and user-defined data, respectively.
Next, the features were sampled from the standardized IBIM cloud data, and the storage method of the data was rationally selected. After that, the storage data were subject to routing, coding, matching feature compression, and adaptive attribute clustering. On this basis, an optimization model was established for the storage structure of IBIM cloud data. To disclose the effects of network coding and matching feature compression on memory usage, the storage nodes in 3D cloud storage model were compared in terms of the compression degree. The results demonstrate that the network coding and matching feature compression can lower the memory usage.
Finally, a batch feature extraction method was designed for 3D structure distribution of job-based 3D cloud storage model, and a complete O&M strategy was developed for the IBIM data in the MapReduce environment. The proposed strategy was proved effective through experiments on job durations.
This paper was supported by the Research on BIM Technology-Based Traffic Engineering Completion Filing and Digital Archive Management Regulations, the Science and Technology Planning Project of the Department of Transportation of Hunan Province in 2019 (Grant No.: 201936) and the Professional Quality and Ability Improvement of BIM Professional Teachers with Double Roles and Abilities in Higher Vocational Education, the Education and Teaching Reform Project of Hunan Vocational Colleges in 2019 (Grant No.: ZJGB2019091).
[1] Carneiro, J., Rossetti, R.J., Silva, D.C., Oliveira, E.C. (2018). BIM, GIS, IoT, and AR/VR integration for smart maintenance and management of road networks: A Review. 2018 IEEE International Smart Cities Conference (ISC2), Kansas City, MO, USA, pp. 1-7. https://doi.org/10.1109/ISC2.2018.8656978
[2] Pasini, D. (2018). Connecting BIM and IoT for addressing user awareness toward energy savings. Journal of Structural Integrity and Maintenance, 3(4): 243-253. https://doi.org/10.1080/24705314.2018.1535235
[3] Arthur, S., Li, H., Lark, R. (2018). The emulation and simulation of internet of things devices for building information modelling (BIM). Workshop of the European Group for Intelligent Computing in Engineering, 325-338. https://doi.org/10.1007/978-3-319-91638-5_18
[4] Rashid, K.M., Louis, J., Fiawoyife, K.K. (2019). Wireless electric appliance control for smart buildings using indoor location tracking and BIM-based virtual environments. Automation in Construction, 101: 48-58. https://doi.org/10.1016/j.autcon.2019.01.005
[5] Dave, B., Buda, A., Nurminen, A., Främling, K. (2018). A framework for integrating BIM and IoT through open standards. Automation in Construction, 95: 35-45. https://doi.org/10.1016/j.autcon.2018.07.022
[6] Sava, G.N., Pluteanu, S., Tanasiev, V., Patrascu, R., Necula, H. (2018). Integration of BIM Solutions and IoT in Smart Houses. 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe (EEEIC / I&CPS Europe), Palermo, pp. 1-4. https://doi.org/10.1109/EEEIC.2018.8494628
[7] Arslan, M., Riaz, Z., Munawar, S. (2017). Building information modeling (BIM) enabled facilities management using hadoop architecture. 2017 Portland International Conference on Management of Engineering and Technology (PICMET), Portland, OR, pp. 1-7. https://doi.org/10.23919/PICMET.2017.8125462
[8] Mohamed, A.G., Abdallah, M.R., Marzouk, M. (2020). BIM and semantic web-based maintenance information for existing buildings. Automation in Construction, 116: 103209. https://doi.org/10.1016/j.autcon.2020.103209
[9] Riaz, Z., Parn, E.A., Edwards, D.J., Arslan, M., Shen, C., Pena-Mora, F. (2017). BIM and sensor-based data management system for construction safety monitoring. Journal of Engineering, Design and Technology, 15(6): 738-753. https://doi.org/10.1108/JEDT-03-2017-0017
[10] Kurian, C.P., Milhoutra, S., George, V.I. (2016). Sustainable building design based on building information modeling (BIM). 2016 IEEE International Conference on Power System Technology (POWERCON), Wollongong, NSW, pp. 1-6. https://doi.org/10.1109/POWERCON.2016.7754039
[11] Lee, K.F., Liu, H.X., Lai, J.Q. (2018). The Application of BIM Technology in Construction Project Cost Management. DEStech Transactions on Social Science, Education and Human Science, (AMSE).
[12] Nahangi, M., Rausch, C., Haas, C. (2016). Optimum assembly planning for modular construction using BIM and 3D point clouds. Modular and Offsite Construction (MOC) Summit Proceedings.
[13] Jin, R., Zhong, B., Ma, L., Hashemi, A., Ding, L. (2019). Integrating BIM with building performance analysis in project life-cycle. Automation in Construction, 106: 102861. https://doi.org/10.1016/j.autcon.2019.102861
[14] Kalyan, T.S., Zadeh, P.A., Staub-French, S., Froese, T.M. (2016). Construction quality assessment using 3D as-built models generated with Project Tango. Procedia Engineering, 145: 1416-1423. https://doi.org/10.1016/j.proeng.2016.04.178
[15] Wang, C., Cho, Y.K. (2014). Automatic as-is 3d building models creation from unorganized point clouds. Construction Research Congress (CRC), ASCE, Atlanta, GA, pp. 917-924. https://doi.org/10.1061/9780784413517.094
[16] Anagnostopoulos, I., Pătrăucean, V., Brilakis, I., Vela, P. (2016). Detection of walls, floors, and ceilings in point cloud data. Construction Research Congress 2016, 2302-2311. http://dx.doi.org/10.1061/9780784479827.229
[17] Čolaković, A., Hadžialić, M. (2018). Internet of Things (IoT): A review of enabling technologies, challenges, and open research issues. Computer Networks, 144: 17-39. https://doi.org/10.1016/j.comnet.2018.07.017
[18] Zhang, S., Hou, D., Wang, C., Pan, F., Yan, L. (2020). Integrating and managing BIM in 3D web-based GIS for hydraulic and hydropower engineering projects. Automation in Construction, 112: 103114. https://doi.org/10.1016/j.autcon.2020.103114
[19] Tang, S., Shelden, D.R., Eastman, C.M., Pishdad-Bozorgi, P., Gao, X. (2019). A review of building information modeling (BIM) and the internet of things (IoT) devices integration: Present status and future trends. Automation in Construction, 101: 127-139. https://doi.org/10.1016/j.autcon.2019.01.020
[20] Guerriero, A., Kubicki, S., Berroir, F., Lemaire, C. (2017). BIM-enhanced collaborative smart technologies for LEAN construction processes. 2017 International Conference on Engineering, Technology and Innovation (ICE/ITMC), Funchal, pp. 1023-1030. https://doi.org/10.1109/ICE.2017.8279994
[21] Ma, Y.P., Lin, M.C., Hsu, C.C. (2016). Enhance architectural heritage conservation using BIM technology. Proceedings of the 21st International Conference of the Association for Computer-Aided Architectural Design Research in Asia CAADRIA 2016, pp. 477-486
[22] McNally, J. (2018). BIM standardization is a challenge worth exploring. PM Engineer, 24(12): 28-28.