Hari Krishna Kanagala* | Vemula Venkata Jayarama Krishnaiah
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The leading eye disease commonly humans suffering is Glaucoma, which cause vision loss by progressively affecting peripheral vision. Presently, glaucoma diagnosis is performed by ophthalmologists, doctors, human professionals with the help of different medical equipment to analyze and understand for identifying the problematic eye images. Detecting glaucoma is a difficult task from the eye images with the help of existing data mining techniques. In this paper, we present an approach for diagnosing of glaucoma with the help of deep learning based techniques fundus images that are analyzed by making use of state-of-the-art deep learning techniques. Specifically, our approach towards glaucoma diagnosis using Convolutional Neural Networks (CNNs) and Varational auto encoder are used. The performance results show the comparative performance of proposed mechanism with state of art mechanisms.
glaucoma, eye, convolution neural networks, machine learning, variable auto encoder, optic disk, medical images, classification
Nowadays, computer techniques have been greatly used in a variety of retinal screening. All retinal structures can be examined analyzed with high modern optical equipment and lenses. Using such equipment gives a view of the optic disk (OD) [1] and an indication of the health of human retina. In particular, the ophthalmologists analyses the color, sharpness of edge, cupping size, swelling, hemorrhages, notching in the OD and other abnormalities.
Therefore, retinal screening is very helpful for finding the diagnosis of glaucoma [2, 3] and other optic neuropathies. However, the screening process is very expensive and time consuming, and requires an expert ophthalmic technician. This implies a progressive need of automated computer-based systems that provides more efficient and less expensive screening.
OD detection plays an important part of the retinal screening to diagnose the eye diseases like diabetic retinopathy and glaucoma, etc. There are greatly many fundus images taken of the standard fundus microscope available at most hospitals and also taken from the fundus is handheld cameras with a portable lenses. Many of the images are imperfect due to the illness of their owners and/or the quality of the cameras.
A faint OD, an invisible OD, an incomplete shape OD [4-9], a too dark/ bright image, and an uneven illumination in an image are examples of imperfect or poor quality images. These images make it difficult for many existing algorithms to obtain good accuracy and also running time.
Generally, existing OD [10-12] detection methods can be categorized into two main approaches, which are appearance-based methods which use the OD features [13, 14] extracted from size, intensity, and colour; and model-based methods which use the geometric correlation that exists between the OD position and the retinal vascular structure in the retina. Appearance-based methods define the OD location as the location of a brightest circular object in the retinal image using the significant OD features.
However, this approach often fails to localize the OD in disease images [15, 16] which have abnormal OD appearances. The model-based techniques are mainly based on the information provided by the vessel network. In addition, this approach highly relies on the extracting and segmentation of retinal vessel structures and detecting the OD location as the convergence point of all retinal vessels. Most current OD detection techniques suffers high computing time. In this work, we propose two OD detection techniques to achieve high accuracy with a very short computing time.
This work mainly focuses on the OD localization techniques. Two techniques for OD localization is proposed in this research. Both techniques mainly utilize the vessel information. In addition, both techniques results high accuracy without high computing time. Figure 1 explains the glaucoma image and components.
Medical imaging [17, 18] is the science of visualising internal body parts by various methods as mentioned in the previous section. Medical imaging has become an inseparable part of modern medicine and is perhaps the most effective means of enabling physician diagnosis. As this field deals with image data, computer scientists have been working closely with medical scientists to provide better diagnostic tools that can be used in real time. Various successful tools have been developed such as the tools for breast cancer detection. This is also applicable in other areas of medicine such as ophthalmology, orthopedics, etc. Retinal imaging is a branch of medical imaging pertaining to the visualization of the retina. There are various methods to obtain such images for research, there are quite a few databases that provide the necessary retinal image data for the purpose of image processing studies as this can help improve diagnostic standards. In this paper section-2 describes the review of literature, section-3 describes the proposed mechanism, section-4 results and discussion and section- concludes the paper.
Figure 1. Glaucoma image and components
A lot of work for mechanized glaucoma recognition so far is performed on shading fundus pictures when contrasted with OCT, CSLO or SLP pictures. Right off the bat, we will look at frameworks situated close by created include extraction pursued by different profound learning based procedures, trailed by move learning frameworks being utilized for mechanized glaucoma identification. The conspicuous methodologies are clarified beneath in detail.
Raghavendra et al. [2] utilized the vitality range based strategy for glaucoma location. At first, optic plate confinement is performed by a hunt window based strategy. After that Radon change (RT) is performed trailed by adjusted evaluation change (MCT). Essence descriptor is framed to portray the picture, which creates loads of highlights. Along these lines the highlights are additionally standardized by utilizing LSDA. SVM is the classifier utilized. This framework has asserted precision of 97.00%.
Maheshwari et al. [3] proposed a novel technique for glaucoma finding. At first, EWT is utilized to picture breakdown into different recurrence groups. After that correntropy highlights are acquired from the picture. At that point highlight positioning is done on the estimation of t esteem include determination calculation. Least squares bolster vector machine classifier groups the picture between glaucomatous or non-glaucomatous picture. This methodology increases in 98.33% exactness for 3 crease approval which are very encouraging.
Rajendra Acharya et al. [4] proposed a novel technique for glaucoma finding utilizing content on and nearby design based highlights. Right off the bat, versatile histogram adjustment is performed, trailed by convolution activity of pictures with different channel banks, bringing about age of textons. Further, LCP is created. Neighborhood arrangement design (LCP) alludes to unmistakable example found in picture. Highlight choice and highlight positioning is finished by SFFS and factual t-test separately alongside K-NN classifier. The framework increases in having 95.8% exactness.
Zilly et al. [5] proposed programmed OC and OD division utilizing a novel technique dependent on CNN. The proposed technique utilized Entropy testing for choosing examining guides which is asserted toward be superior to uniform inspecting. The chose testing indicates are additionally utilized plan a learning arrangement of convolutional channels. The extricated OC and OD can be utilized for CDR count which can additionally be utilized for glaucoma analysis.
Simonthomas et al. [6] proposed robotized glaucoma determination framework by utilizing GLCM and Haralick based surface highlights. In the wake of performing picture preprocessing, thirteen Haralick surface highlights are separated. In this manner, KNN arrangement strategy is applied for ordering fundus picture from being glaucomatous or sound. This framework professes to have 98% exactness in glaucoma location.
Annu and Justin [7], and Gopi et al. [19] proposed a novel strategy for glaucoma recognition utilizing DWT based textural vitality includes alongside Probabilistic neural system classifier. Wavelet highlights are produced utilizing five channels indicated by Raghavendra et al. [9] and Kumar et al. [20]. Z-score standardization is performed in the first place for adjusting the light anomalies. This framework increases in accomplishing 95% precision
Pal et al. [8], and Alahi et al. [21] proposed G-EYENET named autoencoding framework. It comprises of two model framework outline. At first ROI involving OD is acquired from fundus pictures with the utilization of changed u-net CNN containing twofold guide. Auto encoder is utilized for highlight getting the hang of, following which grouping is performed utilizing CNN classifier. HRF, Drishti-GS, RIM ONE v3, datasets are utilized for preparing reason and testing is performed on DRIONS-DB. AUC of 0.923 is accomplished with this.
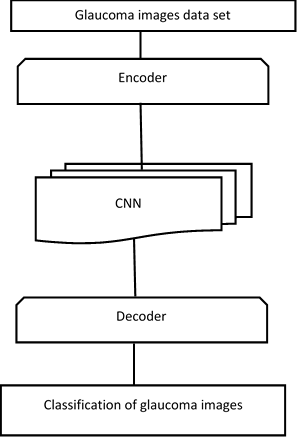
Image processing is a branch of science that deals with the analyzing images to use them for further studies. The steps involved in image processing that are most applicable to this thesis are: Image Enhancement: to refine the quality of image. Image Transformation: These are mathematical operations applied on the image to transform them into spatial domain (default) or frequency domain. In the spatial domain, the image is processed as pixels. In frequency domain, the image is processed in terms of intensity of the image. Image Segmentation: This is the step where the regions of interest are separated into smaller units. Figure 2 describes flow of proposed mechanism.
Figure 2. Proposed glaucoma classification frame work
3.1 Image enhancement
Image enhancement is the first step in image processing. This is undertaken so as to improve quality of the image in terms of clarity inducing details including, but not limited to contrast, detailing, noise-removal, sharpening the image. The end result of image processing is a much clear image with clearly distinguishable objects which make the task of segmentation simpler.
There are many techniques that can be used in image enhancement, some of them are 1. Histogram Equalization: A histogram in image processing is a graph depicting the pixels of an image with respect to the varying intensities. 2. Contrast-Limited Adaptive Histogram Equalization (CLAHE): This method enhances the contrast of the image by breaking down a given image into tile, and enhancing the contrast and re-joining the tiles such that the output is a similar histogram to the parameters set
3.2 Image transformation
Image transforms are mathematical operations that can convert an image from one domain to another. Two important domain transformations relevant to this thesis are:
(1). Spatial Domain Filters: Spatial domain is where pixels can be manipulated relative to each other. Spatial filters can be classified into linear and nonlinear filters.
Linear filters are those filters that change the values of the pixel by a function f(x) when applied. Examples of linear filters are Gaussian, Laplacian, prewitt, etc.
Nonlinear spatial filters use a statistical approach to change the pixel value to a mean or median value. Non-linear filters include median filters, ranking filters etc.
(2). Frequency Domain Filters: Frequency domain is a plane where the image studied is in terms of intensity of the pixels rather than the positioning of the pixels as in spatial domain. Images by default are studied in spatial domain, they can be converted to frequency domain by applying Fourier Transformations. It is not necessary for an image to be converted into frequency domain in order to apply frequency domain filters. Frequency domain filters are classified into high-pass filters, low-pass filters and selective filters.
High-pass filters allows signals at frequencies higher than the threshold to pass, and they attenuate lower frequency signals. These filters sharpen the contrasts in the image.
Low-pass filters allow signals at frequencies lower than the lower threshold to pass while attenuating higher frequencies. These filters smoothen the contrast in the image.
Selective filters operate on smaller regions which require both high-pass and low-pass filtering.
The most used filters in frequency domain are the Gaussian filter and the Butterworth filters. They are implemented as both high pass and low pass filters.
3.3 Segmentation of images
Dividing an image based on regions that are distinctive by the variation of colour or intensity is segmentation. Segmentation is the most crucial step towards the right analysis of an image.
There are numerous approaches to segmentation, some of them are discussed below,
(1). Edge detection: This is an approach where it is imperative to detect the boundaries of regions present within the image. Based on this, the image is segmented into regions. The boundaries are detected by discontinuity of the intensity within the image.
(2). Thresholding: This method differentiates the intensity of pixels from one region to another and segments the image based on a set threshold for high and low intensity.
(3). Region based segmentation: This is a technique where the image is subdivided based on seed points. A seed is a starting point in region based segmentation that has a set of predefined properties such as pixel value or range of color value. This seed point then iteratively expands as more regions with similar properties are added thus resulting in an image that is divided based on regions.
3.4 Feature selection
After segmentation, it is important to ensure that the regions are made to a more optimal data that can easily be processed. The segmented image shall further be divided based on regions of interest. A region of interest is a section of the image that can be further studied so as to arrive at a comprehensive analysis of the image.
3.5 Convolution neural networks (CNN)
CNN is a kind of profound learning model for handling information that has a matrix design, for example, pictures, which is roused by the association of creature visual cortex [13, 14, 22] and intended to naturally and adaptively learn spatial progressions of highlights, from low-to elevated level examples. CNN is a numerical develop that is commonly made out of three sorts of layers (or building squares): convolution, pooling, and completely associated layers. The initial two, convolution and pooling layers, perform include extraction, while the third, a completely associated layer, maps the extricated highlights into definite yield, for example, arrangement. A convolution layer assumes a key job in CNN, which is made out of a heap of numerical tasks, for example, convolution, a particular sort of straight activity. In advanced pictures, pixel esteems are put away in a two-dimensional (2D) framework, i.e., a variety of numbers, and a little matrix of boundaries called piece, an optimizable element extractor, is applied at each picture position, which makes CNNs profoundly effective for picture handling, since an element may happen any place in the picture. As one layer takes care of its yield into the following layer, removed highlights can progressively and continuously become increasingly intricate. The way toward advancing boundaries, for example, pieces is called preparing, which is performed in order to limit the contrast among yields and ground truth names through an enhancement calculation called backpropagation and slope drop, among others.
3.6 Variational auto encoder
Variation auto encoder models inherit autoencoder architecture, but make strong assumptions concerning the distribution of latent variables. They use variational approach for latent representation learning, which results in an additional loss component and specific training algorithm called Stochastic Gradient Variational Bayes (SGVB).
3.7 Training of CNN
Training of CNN here we use random weight initialization mechanism. Weights are independent and identically distributed. Inputs are independent and identically distributed Weights and inputs are mutually independent. The threshold value of training input glaucoma image used is 0.5 or less is taken as Non-glaucoma and more than 0.7 is considered as conformed glaucoma.
3.8 Proposed algorithm
Algorithm glaucoma image classification ()
{
Input: Image data set
Output: classified image data
Step-1: pre-processing
Image Enhancement
Image Transformation
Segmentation of Images
Step-2: Feature selection
VAE and CNN
Step-3: Classification
RNN with VAE
}
Glaucoma image data given to Encoder
The encoder outputs parameters of a distribution Q(z|x).
A latent vector Zz is sampled from Q(z|x).
If the encoder learned to do its job well, most chances are Zz will contain the information describing Xx.
Give the intermediate results came from encoder to CNN
CNN take input and starts learn the minute level features also from the input
The decoder decodes Zz into a final outcome.
On the right side we have the loss:
Reconstruction error: the output should be similar to the input.
Q(z|x) should be similar to the prior (multivariate standard Gaussian).
Convolution: Features from the info picture are extricated in convolutional layer of the CNN. Utilizing little squares of the info information, picture features are found out by convolution which helps save the spatial connection between the pixels. The yield of the convolved picture is known as the convolved feature or enactment map.
The size of the convolved feature is constrained by three parameters:
(1). Profundity: Depth relates to the quantity of parts (channels) we use for the convolution activity.
(2). Walk: Stride is the quantity of pixels by which the piece lattice is slid over the info network. The channels are moved each pixel in turn when the walk is 1, two pixels when the walk is 2, etc.
(3). Zero cushioning: Zero cushioning is utilized to apply the channel for circumscribing component of our info picture.
• Nonlinearity: Nonlinearity in profound systems assumes a significant job in taking in confounded structures from the information. Different kinds of nonlinearities are utilized like Sigmoid, Tanh, ReLU.
• Pooling: Pooling decreases the component of each feature map yet holds the most applicable features. It is likewise called subsampling or down testing. It very well may be of various kinds: normal, whole, max, and so forth.
• Fully Connected Layer: It is essentially a multilayer perceptron that uses a softmax work as initiation work in the yield layer.
4.1 Experimental setup
The proposed method has been tested on two datasets which are Standard Analysis of the Retina, STARE (81 images, 605 x 700 pixels) [7], and Retinopathy of Prematurity, ROP (91 images, 640 x 480 pixels) which is a dataset collected to detect the sign of retinopathy of prematurity from infant patients [1]. The images in two data sets include diabetic retinopathy symptoms, such as exudates, hemorrhages, and other OD abnormal appearances.
STARE (https://cecas.clemson.edu/~ahoover/stare/) and ROP (https://ieee-dataport.org/documents/dnn-classifier-wide-angle-retinal-images-computer-aided-screening-rop) datasets are organized into fair and poor groups. Images which has a bright and obvious boundary of the ODs are assumed as 'fair' and the rest is considered as 'poor'. There are total 81 images in STARE (31 fair quality images and 50 poor quality images) and total 91 images in ROP (60 fair quality images and 31 poor quality images).
The proposed methods were implemented using ANACONDA, Spyder with pyrhon-3 and used matplotlib, numpy packages. Localization and segmentation results shown in the following sub-sections are obtained by running proposed mechanism on a PC (Intel(R) Core(TM) i7 - 4500U CPU @1.8GHz 2.4GHz).
4.2 Results and discussions
Here Figure 3 shows the accuracy of classification for the two data sets STARE and ROPE based on existing and proposed model. The figure shows that in the both cases that is for poor quality images and good quality images existing work fails to make good classification accuracy because of its construction. Here in our machinimas we obtained the best classification accuracy.
Here Figure 4 shows the precession of classification for the two data sets STARE and ROPE based on existing and proposed model. The figure shows that in the both cases that is for poor quality images and good quality images existing work fails to make better precession because of its construction. Here in our machinimas we obtained the best.
Figure 3. Accuracy of classification
Figure 4. Precession of classification
Figure 5. Recall of classification
Here Figure 5 shows the recall of binary classification for the two data sets STARE and ROPE based on existing and proposed model. The figure shows that in the both cases that is for poor quality images and good quality images existing work fails to make good classification recall because of its construction. Here in our machinimas we obtained the good.
Figure 6. F1-score of classification
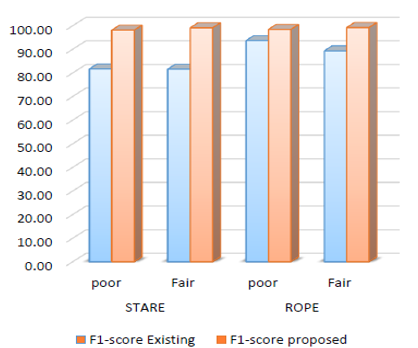
Here Figure 6 shows the F-score of classification for the two data sets STARE and ROPE based on existing and proposed model. The figure shows that in the both cases that is for poor quality images and good quality images existing work fails to make good classification because of its construction. Here in our machinimas we obtained the best F-score.
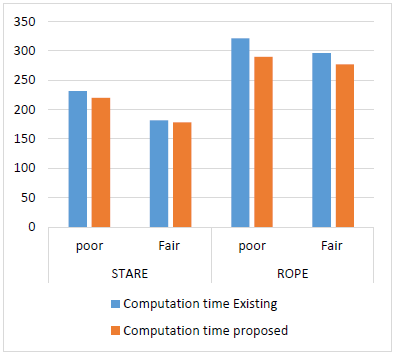
Here Figure 7 shows the computation time of classification for the two data sets STARE and ROPE based on existing and proposed model. The figure shows that in the both cases that is for poor quality images and good quality images existing work fails to make time for made overall computation time because of its construction. Here in our machinimas we obtained good computation time.
Figure 7. Computation time of classification
Glaucoma is a most dangerous and common decease in present era. Predicting glaucoma is a tough and complex task. Glaucoma makes irreversible harm the optic nerve prompting visual deficiency. The optic nerve head assessment, which includes estimation of cup-to disc proportion, is viewed as one of the most important strategies for auxiliary analysis of the illness. Estimation of cup-to-circle proportion requires division of optic plate and optic cup on eye fundus pictures and can be performed by current PC vision calculations. In this paper we propose a mechanism to detect glaucoma effected ones based on an automated CNN based VAE. Proposed mechanism performs well with respect to state of art methods in the literature. We made comparison of state of art methods with proposed with respect to two standard glaucoma data sets STARE and ROPE. Proposed mechanism is good with respect to accuracy and computation time.
[1] Juneja, M., Singh, S., Agarwal, N., Bali, S., Gupta, S., Thakur, N., Jindal, P. (2020) Automated detection of glaucoma using deep learning convolution network (G-net). Multimedia Tools and Applications, 79: 15531-15553. https://doi.org/10.1007/s11042-019-7460-4
[2] Raghavendra, U., Bhandary, S.V., Gudigar, A., Rajendra Acharya, U. (2018). Novel expert system for glaucoma identification using non-parametric spatial envelope energy spectrum with fundus images. Biocybernetics and Biomedical Engineering, 38(1): 170-180. https://doi.org/10.1016/j.bbe.2017.11.002
[3] Maheshwari, S., Pachori, R.B., Acharya, U.R. (2017). Automated diagnosis of glaucoma using empirical wavelet transform and correntropy features extracted from fundus images. IEEE Journal of Biomedical and Health Informatics, 21(3): 803-813. https://doi.org/10.1109/JBHI.2016.2544961
[4] Rajendra Acharya, U, Bhat, S., Koh, J.E.W., Bhandary, S.V., Adeli, H. (2017). A novel algorithm, to detect glaucoma risk using texton and local configuration pattern features extracted from fundus images. Computers in Biology and Medicine, 88: 72-83. https://doi.org/10.1016/j.compbiomed.2017.06.022
[5] Zilly, J., Buhmann, J.M., Mahapatra, D. (2017). Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation. Computerized Medical Imaging and Graphics, 55: 28-41. https://doi.org/10.1016/j.compmedimag.2016.07.012
[6] Simonthomas, S., Thulasi, N., Asharaf, P. (2014). Automated diagnosis of glaucoma using Haralick texture features. Information Communication and Embedded Systems (ICICES 2014), Chennai, India. https://doi.org/10.1109/ICICES.2014.7033743
[7] Annu, N., Justin, J. (2013). Automated classification of glaucoma images by wavelet energy features. International Journal of Engineering and Technology, 5(2): 1716-1721.
[8] Pal, A., Moorthy, M.R., Shahina, A. (2018). G-EYENET: a convolutional autoencoding classifier framework for the detection of glaucoma from retinal fundus images. 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece. https://doi.org/10.1109/ICIP.2018.8451029
[9] Raghavendra, U., Fujita, H., Bhandary, S.V., Gudigar, A., Tan, J.H., Rajendra Acharya, U. (2017). Deep convolution neural network for accurate diagnosis of glaucoma using digital fundus images. Information Sciences, 441: 41-49. https://doi.org/10.1016/j.ins.2018.01.051
[10] Gómez-Valverde, J., Antón, A., Fatti, G., Liefers, B., Herranz, A., Santos, A., Sánchez, C.I., Ledesma-Carbayo, M.J. (2019). Automatic glaucoma classification using color fundus images based on convolutional neural networks and transfer learning. Biomedical Optics Express, 10(2): 892. https://doi.org/10.1364/BOE.10.000892
[11] de Moura Lima, A.C., Maia, L.B., Pereira, R.M.P., J'unior, G.B., de Almeida, J.D.S., de Paiva, A.C. (2018). Glaucoma diagnosis over eye fundus image through deep features. 25th International Conference on Systems, 2018 25th International Conference on Systems, Signals and Image Processing (IWSSIP), Maribor, Slovenia. https://doi.org/10.1109/IWSSIP.2018.8439477
[12] Arepalli, G., Erukula, S.B. (2016). Secure multicast routing protocol in MANETs using efficient ECGDH algorithm. International Journal of Electrical & Computer Engineering, 6(4). http://doi.org/10.11591/ijece.v6i4.pp1857-1865
[13] Alexandrescu, C., Dascalu, A., Panca, A., Sescioreanu, A., Mitulescu, C., Ciuluvica, R., Voinea, L., Celea, C. (2010). Confocal scanning laser ophthalmoscopy in glaucoma diagnosis and management. Journal of Medicine and Life, 3(3): 229- 234.
[14] Allen, L. (1964). Ocular fundus photography: Suggestions for achieving consistently good pictures and instructions for stereoscopic photography. American Journal of Ophthalmology, 57(1): 13-28. https://doi.org/10.1016/0002-9394(64)92027-6
[15] Alsheh Ali, M., Hurtut, T., Faucon, T., Cheriet, F. (2014). Glaucoma detection based on Local Binary Patterns in fundus photographs. Proceedings Volume 9035, Medical Imaging 2014: Computer-Aided Diagnosis, San Diego, California, United States. https://doi.org/10.1117/12.2043098
[16] Aquino, A., Geg'undez-Arias, M.E., Mar'ın, D. (2010). Detecting the optic disc boundary in digital fundus images using morphological, edge detection, and feature extraction techniques. IEEE Transactions on Medical Imaging, 29(11): 1860-1869. https://doi.org/10.1109/TMI.2010.2053042
[17] Bandt, C., Mesing, M. (2009). Self-are fractals of finite type. Banach Center Publications, 84: 131-148. https://doi.org/10.4064/bc84-0-9
[18] Bengtsson, B., Bizios, D., Heijl, A. (2005). Effects of input data on the performance of a neural network in distinguishing normal and glaucomatous visual fields. Investigative Ophthalmology & Visual Science, 46(10): 3730-3736. https://doi.org/10.1167/iovs.05-0175
[19] Gopi, A.P., Babu, E.S., Raju, C.N., Kumar, S.A. (2015). Designing an adversarial model against reactive and proactive routing protocols in Manets: A comparative performance study. International Journal of Electrical and Computer Engineering, 5(5). https://doi.org/10.11591/ijece.v5i5.pp1111-1118
[20] Kumar, S.A., Babu, E.S., Nagaraju, C., Gopi, A. (2015). An empirical critique of on-demand routing protocols against rushing attack in MANET. International Journal of Electrical & Computer Engineering, 5(5): 2088-8708. https://doi.org/10.11591/ijece.v5i5.pp1102-1110
[21] Alahi, A., Ortiz, R., Vandergheynst, P. (2012). FREAK: Fast retina key point. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, pp. 510-517. https://doi.org/10.1109/CVPR.2012.6247715
[22] Chen, X.Y., Xu, Y.W., Wong, D.W.K., Wong, T.Y., Liu, J. (2015). Glaucoma detection based on deep convolutional neural network. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy. https://doi.org/10.1109/EMBC.2015.7318462