Peda Gopi Arepalli* | Vejendla Lakshman Narayana | Rachakonda Venkatesh | Nanduri Ashok Kumar
OPEN ACCESS
Informal community examination is one of the key zones of research amid present day times. The informal community is developing with more clients and the ties between them step by step. It has two parts: separating the versatile interpersonal organization into a few networks by considering data dispersion and choosing networks to discover persuasive hubs by a dynamic programming. A dynamic engendering model considering each the overall quality and individual fascination of the talk is given upheld sensible situation for sure, inside and out totally not the same as existing issues with impact decrease. Specifically, every center is distributed a versatility time limit. If the piece time of each customer outperforms that edge, the utility of the framework will decrease. Our proposed technique can discover new networks dependent on the past structure of the system without recomposing them sans preparation. We present an overview of agent techniques managing these issues and propose a scientific categorization that outlines the best in class. The goal is to give a thorough investigation and guide of existing endeavors around data dissemination in informal communities. The proposed calculation utilizes parallel preparing motor to determine this postpone issue in the present situation. The calculation in parallel discovers the prevalent seed set in the system and extends it in parallel to discover the network. Test results on the engineered and true informal organizations show that our strategy is both viable and proficient in finding networks in unique interpersonal organizations.
social network, greedy calculation, information diffusion, rumor influence, location-based network eager calculation
The expedient advancement and rising nature of huge - scale interpersonal organizations like Twitter, Facebook and so on., numerous in numerable person's region unit prepared to progress toward becoming companions and offer each sort of information with each other [1]. talk concerning partner degree moving toward seismic tremor, which can cause tumult among the gathering and hence could upset the customary open request. amid this case, it's important to find the gossip Source and erase associated messages, which can be sufficient to prevent the talk from any spreading [2]. The previously mentioned difficulties have driven an expansion of looks into in the previous decade on creating methods for impact amplification few individuals could post on informal organizations talk concerning accomplice degree advancing toward shake, which can cause commotion among the social event and thusly could counteract the customary open solicitation [3]. A static grouping strategy is connected on all previews and after that, got networks will be contrasted with each other with track development of network structure over the long haul [4]. Since registering networks is normally free of the previous history, recognized network structure of each specific depiction is significantly not quite the same as the ones identified with different previews, particularly in loud datasets [5]. We bring up qualities and shortcomings of existing methodologies and structure them in scientific categorization [6]. This investigation is intended to fill in as rules for researchers and experts who plan to structure new techniques around there. This additionally will be useful for designers who mean to apply existing systems on explicit issues since we present a library of existing methodologies here [7]. The proposed work is of the last class where the most vital hubs in the network will be distinguished utilizing a parallel predominant seed set choice calculation [8]. The recognized prevalent seeds will be extended by their neighborhood till it achieves the following seed [9].
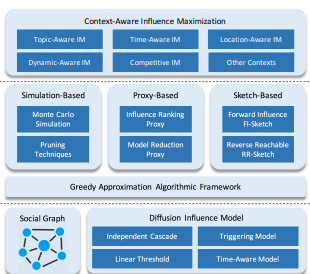
Figure 1. The survey’s overview
This area exhibits the earlier works of the dynamic sensor systems. The creator examined an inclination to advocate a suggestion support for dynamic finding, wherever a client effectively determines a discovering focus to the best of our information [10]. We tend to think about the affordable impact augmentation from new corresponding bearings. One is to upgrade the principal covetous recipe and its improvement to more scale back its timeframe, and furthermore the second is to propose new degree rebate heuristics that improves impact unfurl [11]. The social connections between clients other than viral showcasing, IM is additionally the foundation in numerous other vital applications, for example, organize observing gossip control and social proposal [12]. We address the matter of constraining the expansion of troublesome things, like pc contaminations or poisonous bits of gossip by block a kept extent of associations [13].
In spite of the fact that they achieved higher precision contrasted and the other nearby network discovery strategies, however because of high time unpredictability of their methodology, it isn't adaptable in discovering networks in huge informal communities. Seed-driven methodology isn't constrained to the neighborhood network location issue [14]. An OSN is formally spoken to by a diagram, where hubs are clients and edges are connections that can be either coordinated or not relying upon how the SNS oversees connections [15].
All the more accurately, it relies upon whether it permits associating in a one-sided way. Messages are the fundamental data vehicle in such administrations [16]. There is parcel of seed determination calculations accessible for various applications. Every application may need to embrace diverse seed choice calculations which coordinate the application prerequisite. For instance if the application is a showcasing application, the out-degree centrality or the page rank centrality might be utilized for the seed determination process [17].
The conventional Influence Maximization issue goes for finding powerful hubs for just single static interpersonal organization true informal organizations are only here and there static. Both the structure and furthermore the impact quality related with the edges change continually [18]. Acknowledgment probability Maximization (APM), and build up a polynomial time rule known as Selective welcome with Tree and In-Node Aggregation (SITINA), to search out the best goals.
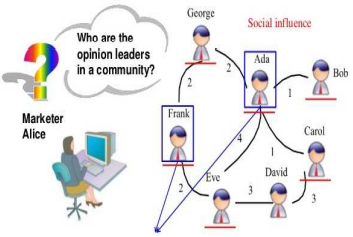
Figure 2. Group of social users
We tend to actualize a brimming with life discovering administration with SITINA on Face book to approve our arrangement [19]. The impact of any seed set is characterized dependent on the data dispersion process among the clients the data dissemination is viral promoting, where an organization may wish to spread the reception of another item from some underlying adopters through the social connections between clients [20].
We propose gossip proliferation show thinking about the ensuing 3 components: starting, the overall nature of the talk over the entire informal community, i.e., the last subject elements. Second, the fascination elements of the gossip to a conceivable spreader, Third, the acknowledgment shot of the talk beneficiary [21]. Distinctive models apply diverse systems to catch how a client changes its status from dormant to dynamic, which is impacted by its neighbors. This area just spotlights on four agent models that are ordinarily utilized in the IM issue, to be specific Independent Cascade (IC) demonstrate, Linear Threshold (LT) show, Triggering (TR) model, and Time Aware model. We likewise quickly examine regular non-dynamic dissemination models [22]. Powerful Node Tracking on Dynamic Social Network: An Interchange Greedy Approach: In this paper we tend to explore a unique downside, particularly appropriate Node seek after disadvantage, as A growth of Influence Maximization disadvantage to dynamic frameworks [23].
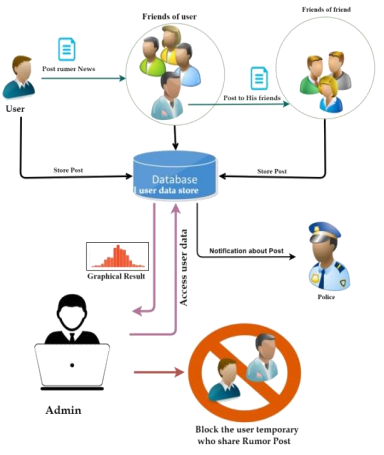
Figure 3. System architectire of social network data base access
The principle thought A decent network structure in a dynamic interpersonal organization is one in which the individuals ought to have a solid organized comparability with one another and they should keep this similitude after some time. Therefore, any strategy whose point is to distinguish and follow networks in unique informal organizations ought to think about two primary attributes:
Detected people group ought to be measured at each time step. As it were, hubs firmly associated with each other, must be assembled in a similar group [24].
Algorithm: K-means Alogorithm
(1). Let X={x1,x2,x3,……,xn}be the set of post and V={v1,v2,……,vc} be the set of users.
(2). Arbitrarily select ‘c’ cluster ofcuses.
(3). Calculate the connection between each tweet and (client) cluster focuses.
(4).Assign the tweet to the cluster focus whose connection with cluster focus solid of all the cluster focuses.
(5). Recalculate the new cluster focus utlizing: where, “ci” represnets the number of data points in ith cluster.
${{V}_{t}}=(1/{{C}_{S}})\sum\nolimits_{j=1}^{Ci}{\left( \begin{matrix} n \\ k \\ \end{matrix} \right)}xi$
(6). Recalculate the connection amongst post and new acquired cluster focues.
(7). If no post was reassigned then stop, generally rehash from stage 3)
(8). 2-Temporal smoothness of clusters over consecutive snapshots should be preserved; that is, in most of the cases, the communities of time t should not sharply differ from the ones of time t-1.
Algorithm: Dynamic Blocking Algorithm
Different from the greedy blocking algorithm, which is a type of static blocking algorithm, we propose a dynamic rumor blocking algorithm aimning to incrementally block the selected nodes instead of blocking them at once. In that case the blocking strategy is split into several rounds and each round can be regarded as a greedy algorithm. Thus, how to choose the number of rounds is also very important for the algorithm [25]. We will elaborate on the algorithm design and how we choose the specific parameters.
Input: Iitial Edge matrix A0
Initialization: VB(t)=0.
for j=l to n do
for i =l to kj do
$∆f=f(tj│s(tj-1);Ai-1)-f(tj|s(tj-1);Ai-1\v)$
$u=arg max {∆f}$
Ai: =Ai-1\u,
VB(tj)=VB(tj)U{u}.
end for
end for
Output: VB(t).
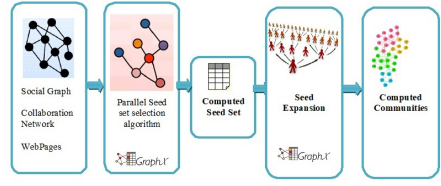
Parallel predominant seed set choice calculation extricates the critical hubs in the information diagram. The information will be put away in the appropriated document framework for further handling [25]. Centrality measures are utilized to coin out the critical hubs in the system [26]. Every centrality measure will have its own significance and use cases to deal with. Joining these centrality measures can recognize great seeds over all the centrality measures.
Figure 4. Parallel community detections framework
Algoritbm Parleluperor Seed StSlection Algortbm (P4S)
1: procedure P4S(g, τ) $\triangleleft $ Parllel Superior Seed set selecio(P4S)
2: READ graph G(V,E)
3: COMPUTE
4: degree centrality d
5: eigen value centrality e
6: local clustering coefficient 1
7: page rank cetrality p $\triangleleft $ Parallel
8: SORT d, e, l , p
9: for δ do $\triangleleft $ Parallel
10: Threshold τ ←vertex count/δ
11: Fetch τ count of top nodes from list of d, e, l, p
12: lntertsect (d,e,l,p)
13: return Superior Seeds Set S(g)
The threshold value will be used to split the top ranks for all measures. Finally, set intersection of the top nodes from each centrality measure will be done to get the superior seed set depicts the process of finding the superior seed set.
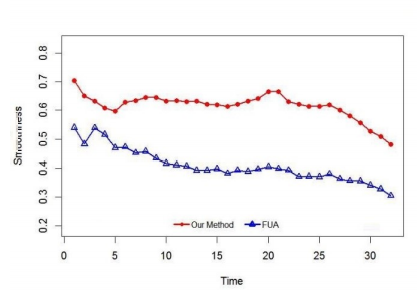
Figure 5. Temporal smoothness of dynamic grouping techniques on genuine informal organization
The execution of the proposed strategy we directed thorough analyses on both PC created systems and genuine unique ones. Two systems produced by PC and furthermore a few genuine unique systems were researched. Contemplating the steadiness of the pioneers and non-pioneer hubs on genuine informal organization demonstrates that the network heads of the proposed definition are considerably steadier in contrast and devotee hubs. In addition the runtime consequences of these two datasets are disregarded for Facet Net strategy since the comparing procedure required more memory than the sum accessible in the test machine. Clearly the proposed technique will be more adaptable than the current work, in standing up to with enormous powerful informal community.
The informal communities are a noteworthy research issue we proposed a quick without parameter technique to discover important networks in very powerful interpersonal organization. Network based Greedy calculation is utilized for mining top-K compelling hubs. It has two segments: partitioning the portable interpersonal organization into a few networks by considering data dissemination and choosing networks to discover powerful hubs by a dynamic programming. A dynamic gossip dissemination show consolidating both worldwide talk ubiquity and individual propensity is displayed dependent on proposes an adjusted variant of utility capacity to quantify the connection between the utility and blocking time. For future works, we intend to research the lifetime advancement of these promising individuals in different powerful interpersonal organizations. This data will be utilized to catch the principle attributes of such systems and empowers us to foresee the approaching structure of systems.
[1] Chen W, Wang Y, Yang S. (2009). Efficient influence maximization in social network. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, pp. 199–208. https://doi.org/10.1145/1557019.1557047
[2] Arora A, Galhotra S, Ranu S. (2017). Debunking the myths of influence maximization: An in-depth benchmarking study. The 2017 ACM International Conference, pp. 651–666. https://doi.org/10.1145/3035918.3035924
[3] Chen S, Fan J, Li GL, Feng JH, Tan KI, Tang JH. (2015). Online topic-aware influence maximization queries. Proceedings of the VLDB Endowment 8(6): 666-667.
[4] Barbieri N, Bonchi F, Manco G. (2012). Topic-aware social influence propagation models. Knowledge and Information Systems 37(3): 81–90. https://doi.org/10.1007/s10115-013-0646-6
[5] Bharathi S, Kempe D, Salek M. (2007). Competitive influence maximization in social networks. Springer Berlin Heidelberg 2007: 306-311. https://doi.org/10.1007/978-3-540-77105-0_31
[6] Borgs C, Brautbar M, Chayes J, Lucier B. (2012). Maximizing social influence in nearly optimal time. Computer Science, 946–957. https://arxiv.org/abs/1212.0884
[7] Borodin A, Filmus Y, Oren J. (2010). Threshold models for competitive influence in social networks. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), pp. 539–550. https://doi.org/10.1007/978-3-642-17572-5_48
[8] Budak C, Agrawal D, El-Abbadi A. (2011). Limiting the spread of misinformation in social networks. Proceedings of the 20th International Conference on World Wide Web, WWW 2011, Hyderabad, India, pp. 665–674. https://doi.org/10.1145/1963405.1963499
[9] Carnes T, Nagarajan C, Wild SM, Zuylen VA. (2007). Maximizing influence in a competitive social network: A follower’s perspective. Proceedings of the 9th International Conference on Electronic Commerce: The Wireless World of Electronic Commerce, 2007, University of Minnesota, Minneapolis, MN, USA, pp. 351–360. https://doi.org/10.1145/1282100.1282167
[10] Chen S, Fan J, Li G, Feng J Tan K, Tang J. (2015). Online topicaware influence maximization. Proceedings of the VLDB Endowment 8(6): 666–677. https://doi.org/10.14778/2735703.2735706
[11] Gopi A, Babu ES, Raju CN, Kumar SA. (2015). Designing an adversarial model against reactive and proactive routing protocols in MANETS: A comparative performance study. International Journal of Electrical & Computer Engineering, 505-512.
[12] Crane R, Sornette D. (2008). Robust dynamic classes revealed by measuring the response function of a social system. Proceedings of the National Academy of Sciences of the United States of America 105: 15649-15653. https://doi.org/10.1504/IJICA.2008.078727
[13] Bikku T, Rao NS, Rao AA. (2017). A Novel multi-class ensemble model for classifying imbalanced biomedical datasets. In IOP Conference Series: Materials Science and Engineering 225(1): 012161. https://doi.org/10.1088/1757-899X/225/1/012161
[14] Vejendla LN, Bharathi CR. (2018). Multi-mode routing algorithm with cryptographic techniques and reduction of packet drop using 2ACK scheme in MANETs. Smart Intelligent Computing and Applications 1: 649-658. https://doi.org/10.1007/978-981-13-1921-1_63
[15] Kempe D, Kleinberg J, Tardos E. (2003). Maximizing the spread of influence through a social network. In Proceedings of the 9th ACM SIGKDD Internatioanl Conference on Knowledge Discovery and Data Mining, pp. 1175–1180. https://doi.org/10.1145/3075564.3078884
[16] Lin YR, Chi Y, Zhu S, Sundaram H, Tseng BL. (2009). Analyzing communities and their evolutions in dynamic social networks. ACM Trans. Knowl. Discov. Data 3(2): 131. https://doi.org/10.1145/1514888.1514891
[17] Palla G, Dernyi I, Farkas I, Vicsek T. (2005). Uncovering the overlapping community structure of complex networks in nature and society. Nature 435: 814-818.
[18] Vejendla LN, Bharathi CR. (2018). Effective multi-mode routing mechanism with master-slave technique and reduction of packet droppings using 2-ACK scheme in MANETS. Modelling, Measurement and Control A 91(2): 73-76. https://doi.org/10.18280/mmc_a.910207
[19] Gopi AP, Vejendla LN, Kumar NA. (2018). Dynamic load balancing for client server assignment in distributed system using genetical gorithm. Ingénierie des Systèmes d'Information 23(6): 87-98.
[20] Bikku T, Nandam SR, Akepogu AR. (2018). A contemporary feature selection and classification framework for imbalanced biomedical datasets. Egyptian Informatics Journal 19(3): 191-198. https://doi.org/10.1016/j.eij.2018.03.003
[21] Vejendla LN. Gopi AP. (2017). Visual cryptography for gray scale images with enhanced security mechanisms. Traitement du Signal 35(3-4): 197-208.
[22] Mu CH, Xie J, Liu Y, Chen F, Liu Y, Jiao LC. (2015). Memetic algorithm with simulated annealing strategy and tightness greedy optimization for community detection in networks. Applied Soft Computing Journal 34: 485–501. https://doi.org/10.1016/j.asoc.2015.05.034
[23] Salihoglu S, Widom J. (2013). GPS: A graph processing system. SSDBM Proceedings of the 25th International Conference on Scientific and Statistical Database Management. Proceedings of the 25th International Conference on Scientific and Statistical Database Management - SSDBM (2013) 1. https://doi.org/10.1145/2484838.2484843
[24] Gopi AP, Vejendla LN. (2017). Protected strength approach for image steganography. Traitement du Signal 35(3-4): 175-181.
[25] Conde LES, Romance M, Herrero RC, Flores J, Amo, AG, Boccaletti S. (2013). Eigenvector centrality of nodes in multiplex networks. Chaos 23(3): 1–11. https://doi.org/10.1063/1.4818544
[26] Kleinberg J. (2002). Bursty and hierarchical structure in streams. Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and data Mining, pp. 91–101. https://doi.org/10.1145/775047.775061